Pebble 源码剖析-写入流程
本章会结合 Pebble 源码来剖析整个写入流程,并会深入分析整个写入路径上涉及的一些技术细节。这里说明,文章只会贴一些关键代码和代码行数较少的函数或者方法,尽量避免太多代码内容影响阅读感受。
预备知识
为了便于大家理解,首先会科普一些基础概念,有基础的同学可以直接跳过。为了更直观的理解,我们先将 上一章 的图搬过来。
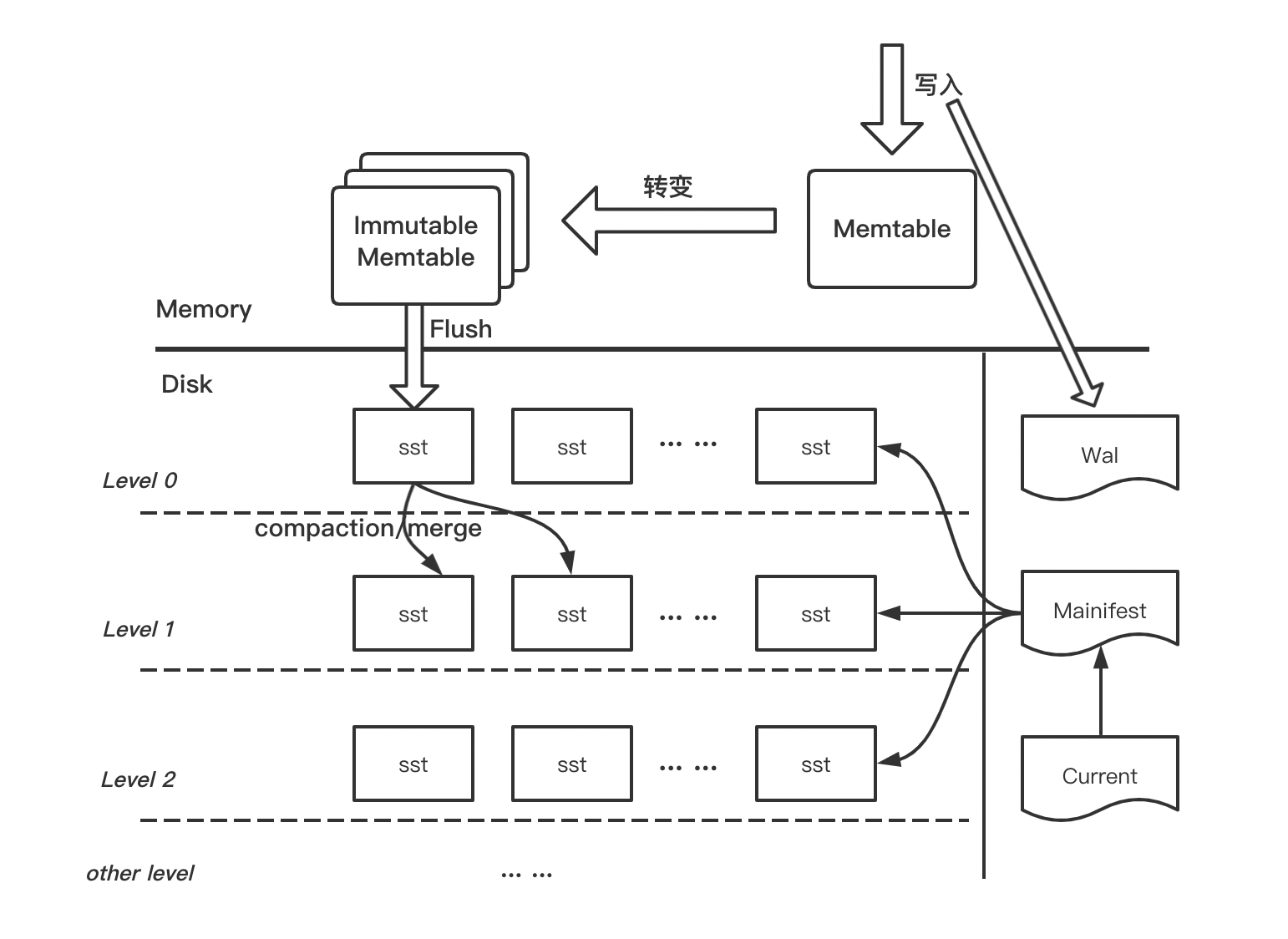
WAL
Wal(Write ahead of log)即预写日志,其是一种日志结构,每条日志包含了数据的原始内容并以追加写的方式写入磁盘文件,在数据写入内存前需将原始数据写入到 Wal。Wal 的写入模式可以分为 Sync(同步)和 Async(异步),如果为同步写则前台需阻塞等待日志落盘,异步写只需将日志记录写到内存缓存后便可返回。因此,同步模式可靠性更高但性能偏低,异步模式性能很好但有丢数据的风险,需根据具体场景合理选择使用哪种模式。Wal 的具体格式会在下面源码分析阶段详细介绍。
Memtable
Memtable 是数据(KV Pairs)在内存中的载体,业务数据写入 Pebble 后,首先写 Wal,然后会写入到 Memtable,数据在 Memtable 中会按序存储。Memtable 有两种形式,一种是 Mutable Memtable(可变),另外一种是 Immutable Memtable(不可变),顾名思义,前者可以同时支持读写,而后者只能读不能写。Memtable(默认指是 Mutable)一般会有大小限制,写满后会转变为 Immutable,Immutable 会由专门后台线程按照某种策略刷到磁盘,同时释放内存并清理对应的 Wal。
SSTable
SSTable 即 Sorted String Table 简称为 SST,由内存中的 Memtable 刷盘而成,是一种有序的、不修改的磁盘文件格式,其中 Key 和 Value 都可以是任意的 byte 序列。和 RocksDB/LevelDB 一样,SST 在 Pebble 中也是按层组织,数据首先刷入到第 0 层,在到达一定数量后后被后台线程 Merge 并 Compact 到下层。每层的数据量按倍数增长,越往下层数据量越大,同时数据也越老。
由于本章只分析写入流程,因此我们先科普上述三个比较重要的概念,其他知识后面涉及再详细展开。
源码分析
有了上面的预备知识,本节可以开始对源码进行剖析了。首先贴上官方的 Demo 程序:
package main
import (
"fmt"
"log"
"github.com/cockroachdb/pebble"
)
func main() {
db, err := pebble.Open("demo", &pebble.Options{})
if err != nil {
log.Fatal(err)
}
key := []byte("hello")
if err := db.Set(key, []byte("world"), pebble.Sync); err != nil {
log.Fatal(err)
}
value, closer, err := db.Get(key)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s %s\n", key, value)
if err := closer.Close(); err != nil {
log.Fatal(err)
}
if err := db.Close(); err != nil {
log.Fatal(err)
}
}
可以看到 Pebble 的使用还是比较简单,首先根据配置项打开一个 DB,然后便可以向该 DB 进行读写操作了。这里顺便介绍配置项 Options 的一些常用且重要的选项,便于后续理解。
BytesPerSync // 控制 sstable 按照该值平滑刷盘,防止系统一次性刷大量脏页导致写入延时抖动,默认值是 512KB
WALBytesPerSync // 控制 wal 按照该值平滑刷盘,不过 Pebble 认为该值一般情况下没必要设置,因为大部分场景 wal 是 sync 写入的,默认值是 0
DisableWAL // 是否关闭 Wal,该参数为 true 时,不写 Wal,数据可靠性最低,默认为 false
L0CompactionThreshold // level 0 读放大 compaction 阈值,到达阈值后将触发 L0 compaction,默认值是 4
L0StopWritesThreshold // level 0 的读放大停写阈值,达到阈值后将阻塞写,默认值是 12
LBaseMaxBytes // level 0 compaction 至的 level 最大容量,其他层的最大容量会根据该值动态计算,默认是 64 MB
MemTableSize // memtable 的最大值,memtable 的大小从 256KB 开始分配,每次新建则翻倍直到达到该阈值,默认是 4MB
MemTableStopWritesThreshold // 所有 memtable 总大小达到 MemTableStopWritesThreshold*MemTableSize 会阻塞写,默认值是 2
MaxConcurrentCompactions // 最大 compaction 并发数,默认值是 1,具体用处等到后面将 compaction 时再详细展开
ReadOnly // DB 以只读方式打开,后台的 compaction 和 flush 会关闭
了解上述基本配置项后,现在可以正式进入写入流程。这里展示不分析 Open 流程,等介绍完前几章内容再倒过来分析会更容易理解。我们直接从 DB.Set 开始。
DB.Set
数据的写入方式有两种,一种是单 KV 写入,另一种是 Batch 批量写入。单 KV 写入也会转为 Batch 方式,因此我们以 DB.Set 方法为入口来看看里面的实现逻辑。
func (d *DB) Set(key, value []byte, opts *WriteOptions) error {
b := newBatch(d)
_ = b.Set(key, value, opts)
if err := d.Apply(b, opts); err != nil {
return err
}
// Only release the batch on success.
b.release()
return nil
}
可以看到,Set 方法内部会新建一个 Batch,并将 KV 塞入到 Batch,然后执行 DB 的 Apply 方法,如果成功执行则调用 release 释放 Batch。这里讲到 Batch,那我们来看看 Batch 的格式到底长啥样。
|- header -|- body -|
+-----------+-----------+----...--+
|SeqNum (8B)| Count (4B)| Entries |
+-----------+-----------+---------+
Batch 内部数据由 header 和 body 组成,header 包含 8 字节 SeqNum 和 4 字节 Count,SeqNum 表示 batch 的序列号,Count 表示 Entry 个数。body 由多个 Entry 构成。每个 Entry 格式如下:
+----------+--------+-----+----------+-------+
|Kind (1B) | KeyLen | Key | ValueLen | Value |
+----------+--------+-----+----------+-------+
Kind 表示 Entry 的类型,如 SET、DELETE、MERGE 等,这里写入的类型为 SET。KeyLen 表示 Key 的大小,为 VInt 类型,最大 4 字节,Key 即为 KeyLen 字节序列,同理,ValueLen 表示 Value 大小,为 VInt 类型,最大 4 字节,Value 为 ValueLen 字节序列。
了解完 Batch 格式后,我们继续往下走,这里直接进入到 DB 的 Apply 方法。
DB.Apply
Apply 方法里面会做一些检验工作,随后将 Batch 提交写入,这里贴部分关键代码:
if int(batch.memTableSize) >= d.largeBatchThreshold {
batch.flushable = newFlushableBatch(batch, d.opts.Comparer)
}
if err := d.commit.Commit(batch, sync); err != nil {
// There isn't much we can do on an error here. The commit pipeline will be
// horked at this point.
d.opts.Logger.Fatalf("%v", err)
}
首先会判断 batch 的大小,如果超过最大 large batch 的阈值,则该 batch 被视为 large batch,需要特殊处理。为了避免本章内容过于繁杂,本章后面所有涉及 large batch 的逻辑都将省略,下章会单独对 large batch 进行讲解。下面我们直接进入 Commit 方法。
commitPipeline.Commit
笔者认为 Commit 方法是写入流程中非常核心的方法,里面体现了 Pebble 高性能设计之道。我们先来看看代码(该方法不算特别长,全部奉上):
func (p *commitPipeline) Commit(b *Batch, syncWAL bool) error {
if b.Empty() { return nil}
// 并发控制,sem 是缓冲 channel,因此可以并发 commit
p.sem <- struct{}{}
// prepare 主要做的事情:1. 准备好可用的 memtable 2. 写 wal(可以是异步的,将 wal 塞入 queue, 再异步写,提高并发性能)
// prepare 中会对 pipeline 加锁,因此整个过程是串行执行,不过该函数通常很快
mem, err := p.prepare(b, syncWAL)
if err != nil {
b.db = nil // prevent batch reuse on error
return err
}
// 将 batch 写入 memtable,这里可以是并发执行,该流程是 pipeline 中最耗的
if err := p.env.apply(b, mem); err != nil {
b.db = nil // prevent batch reuse on error
return err
}
// Publish the batch sequence number.
p.publish(b)
<-p.sem
if b.commitErr != nil {
b.db = nil // prevent batch reuse on error
}
return b.commitErr
}
Commit 方法包含三个核心步骤,首先是通过 prepare 方法准备好可用的 Memtable,并将数据异步写入 Wal,整个 prepare 方法会加锁,因此该方法只能串行执行,但是该方法执行较快,时间复杂度为 O(1) ;然后调用 apply 方法将 batch 写入 Memtable,由于 Memtable 采用无锁 Skiplist 实现,可以并发执行,但是该流程相对更耗,时间复杂度为 nO(logm)(n 为 Batch 记录条数,m 为 Memtable 中 key 数目);最后调用 publish 方法将 batch 的 SeqNum 发布出去使其可见,换句话说,就是让提交的数据可读,该函数可并发执行,如果 Wal 为异步落盘,该方法会比较快。在多线程场景下,这三个阶段会被组织成 Pipleline 方式处理,我们先根据下图来直观感受下 Pipeline 的执行过程:
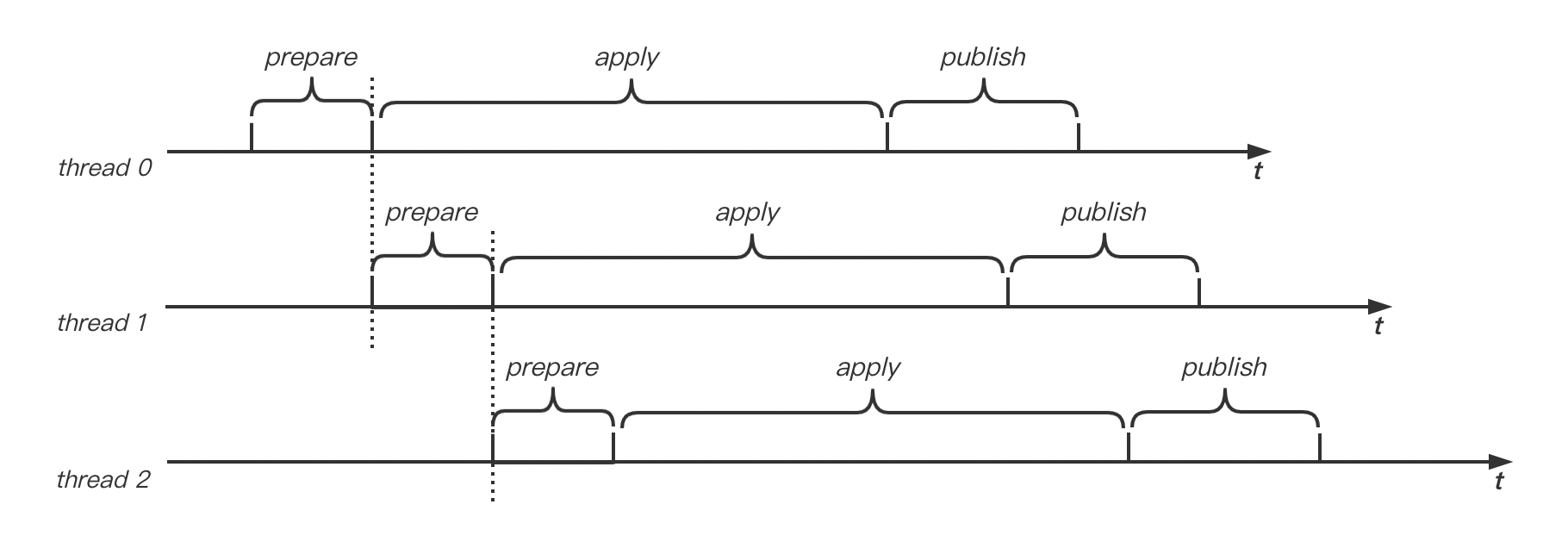
如上图,假设有多个线程并发执行 Commit,只有 prepare 阶段间多个线程是串行执行,其他阶段是可以并发执行的,这种思想和处理器指令流水线如出一辙。这种模型可以充分发挥现代 CPU 多核的优势。我们可以通过一个公式来计算下每个线程的平均耗时。假设每个线程的 prepare 阶段耗时为 x,apply 耗时为 y,publish 耗时为 z。则从第 1 个线程到第 n 个线程执行完毕,时间轴上总耗时为 n * x+y+z,每个线程的平均耗时为 (n * x+y+z)/n = x+(y+z)/n。可以看出在理想情况下,并发量无穷大时,线程的平均执行时间趋近于 x,当然实际上线程数过多并不一定更优,因为线程切换也是有开销的,总的来说,在合理范围内,并发量越大系统吞吐也更大。
到这里,Pipeline 的设计思想就分析完成了。接下来我们再展开讲讲每个阶段的执行逻辑。
commitPipeline.prepare
prepare 方法主要是准备 batch 写入的 Memtable 及异步写 wal。主要代码如下:
count := 1
if syncWAL {
count++
}
// commit 为 sync.Group,用于等待 batch publish,如果 wal 为同步模式,也会等待 wal 刷盘
b.commit.Add(count)
p.mu.Lock()
// 将 batch 如队列,保证并发场景下 batch 的顺序
p.pending.enqueue(b)
// 设置 batch 的序列号,batch 的 n 条记录序列号递增
b.setSeqNum(atomic.AddUint64(p.env.logSeqNum, n) - n)
// 将数据写入 wal
mem, err := p.env.write(b, syncWG, syncErr)
p.mu.Unlock()
首先会根据 Wal 是否为同步模式来决定 commit 的等待计数,初始计数为 1,是因为必须等待 batch 的发布(后面 publish 方法中会看到),如果 Wal 为同步模式,还必须等待 Wal 刷盘完成。注意,这里只是计数,commit.Wait 会在 publish 中调用。
然后加锁进入临界区,在临界区内,先将 batch 入队列;然后给 batch 分配递增的序列号,由于外面有上锁,因此在并发环境下,batch 在队列中的顺序和 SeqNum 的顺序关系一致,即先入队列的 SeqNum 越小;最后将数据写入 wal。这里的 write 方法其实是 DB.commitWrite,我们来看下写入的逻辑。
DB.commitWrite
这个方法里面会执行两个核心的操作:1. 准备 batch 的 Memtable;2. 将数据写入到日志的内存结构中。贴下关键代码:
// 获取 batch 的底层字节数组数据
repr := b.Repr()
// 上锁,操作 memtable
d.mu.Lock()
err := d.makeRoomForWrite(b)
mem := d.mu.mem.mutable
d.mu.Unlock()
// 如果 wal 未开启,直接返回 memtable
if d.opts.DisableWAL {
return mem, nil
}
// 将数据写入 wal 内存结构
if b.flushable == nil {
size, err = d.mu.log.SyncRecord(repr, syncWG, syncErr)
if err != nil {
panic(err)
}
}
makeRoomForWrite 主要是为了确保当前 Memtable 是否足以容纳 batch 的数据,如果当前 Memtable 容量已经满了,会将其转变为 Immutable 并重新创建 Memtable。由于 makeRoomForWrite 会对 memtable 和 log 进行操作,因此这里会加锁,该方法执行逻辑比较复杂,这里不详细展开,我们放到下章和 large batch 一起讲解。
如果开启了 Wal,会将数据写入日志内存结构。这里我们来看看日志的格式:
|- header -|- body -|
+---------+-----------+-----------+----------------+--- ... ---+
|CRC (4B) | Size (2B) | Type (1B) | Log number (4B)| Payload |
+---------+-----------+-----------+----------------+--- ... ---+
日志由 header 和 body 构成。header 包含 4 字节 CRC 校验码,2 字节 Size 表示 body 的大小,1 字节 Type 表示日志处在 block 中的位置,后面详细解释, 4 字节 LogNum 表示日志文件的编号,可用于日志复用,这个后面章节再详解;payload 表示日志的内容,在这里即为 Batch 的字节数组数据。
日志是按照 32KB 的 Block 来存放的,如下图所示:
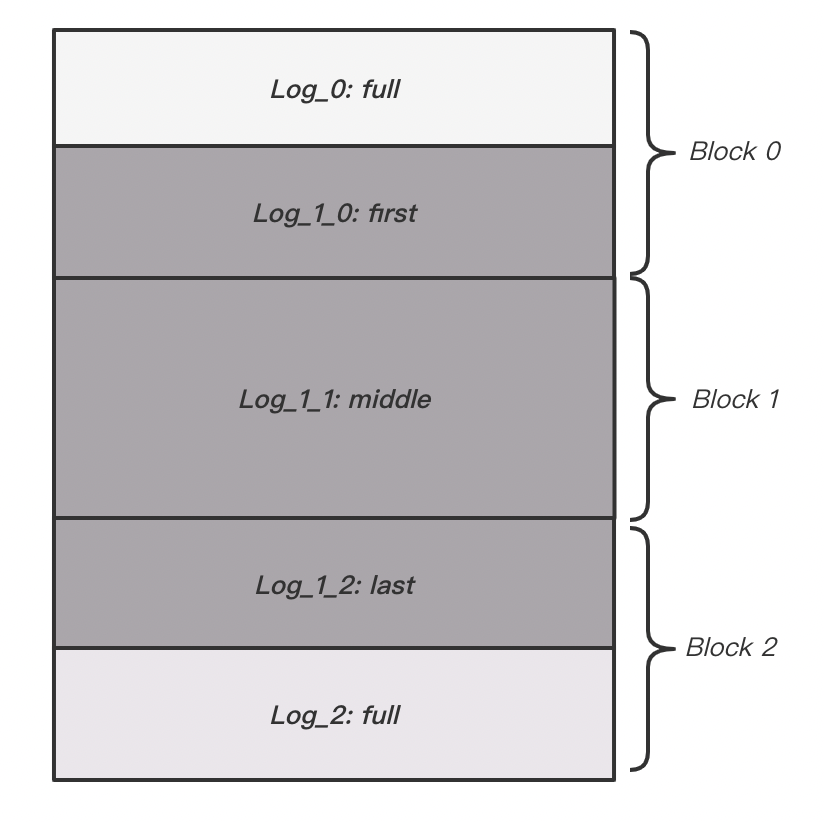
如果一条日志比较小,足以放入到 1 个 Block 中,此时 Type 即为 full,如果一条日志比较大,那么 1 个 Block 无法放入,那么一条日志便会切分成多个片段跨多个 Block 存放,第一个片段的 Type 为 first,中间片段的 Type 为 middle,最后一个片段的 Type 为 last。读取日志时,便可根据 Type 将日志组装还原。
有了上面对日志格式的讲解,我们再看 SyncRecord 方法就比较容易了,LogWriter.SyncRecord 的代码如下:
func (w *LogWriter) SyncRecord(p []byte, wg *sync.WaitGroup, err *error) (int64, error) {
// 切分数据放到片段中
for i := 0; i == 0 || len(p) > 0; i++ {
p = w.emitFragment(i, p)
}
// wg 不为空,则表示 wal 是同步落盘,因此需要通知 flusher 去刷盘
if wg != nil {
f := &w.flusher
f.syncQ.push(wg, err)
f.ready.Signal()
}
offset := w.blockNum*blockSize + int64(w.block.written)
return offset, nil
}
SyncRecord 方法还是比较好理解,for 循环中便会将数据按照上面讲的方式切分片段,并将片段写入 block 中。如果日志为同步落盘方式,还会通知 flusher 去刷盘,同时会将 wg 放到 sync 队列,flusher 会通过 wg 异步通知 Pipeline 刷盘完成。
到这里,通过 prepare 阶段已经将 Memtable 准备完毕,同时讲数据写入到 Wal 内存 Block 中,Pipeline 流程便会拿着准备好的 Memtable 进行写入操作,我们继续看下一个阶段 apply。
commitPipeline.commitEnv.apply
上一阶段已经准备好 Memtable,在 apply 阶段便会将 batch 写入到 Memtable 中。apply 的代码如下:
func (d *DB) commitApply(b *Batch, mem *memTable) error {
// 写入 memtable,无锁
err := mem.apply(b, b.SeqNum())
if err != nil {
return err
}
//
if mem.writerUnref() {
d.mu.Lock()
d.maybeScheduleFlush()
d.mu.Unlock()
}
return nil
}
这里省略了部分代码,commitAppy 方法中,首先会将 batch 写入 memtable,memtable 内部是无锁 Skiplist,支持并发读写;写入完毕后释放 memtable 的写引用,最后调用 DB.maybeScheduleFlush 决定是否将 memtable flush 到磁盘,该方法是异步执行的,因此临界区耗时较短,flush 的流程我们放到后面剖析 compaction 的章节去讲。
apply 完毕后,数据就已经成功写入到 memtable 中,这时候写入流程还并未结束,数据还不能读取到。我们继续看下一阶段 publish。
commitPipeline.publish
回顾下 prepare 阶段,batch 的 commit 被计数,commit 为 sync.Group,主要用途是:1. Wal 如果是同步落盘,需等待 wal 落盘完毕;2. 等待 batch 的 SeqNum 被发布。接下来看看 publish 的实现逻辑:
func (p *commitPipeline) publish(b *Batch) {
// 标记当前 batch 已经 apply
atomic.StoreUint32(&b.applied, 1)
for {
// 从队列取出 batch,该 batch 可能是当前 batch,也可能是其他线程提交的 batch
t := p.pending.dequeue()
if t == nil {
// 关键,1. 等待 SeqNum 被发布 2. 如果 wal 同步落盘等待 flusher 通知落盘
b.commit.Wait()
break
}
if atomic.LoadUint32(&t.applied) != 1 {
panic("not reached")
}
// 通过循环 + cas 的方式更新当前可见的 SeqNum
for {
curSeqNum := atomic.LoadUint64(p.env.visibleSeqNum)
newSeqNum := t.SeqNum() + uint64(t.Count())
if newSeqNum <= curSeqNum {
// t's sequence number has already been published.
break
}
if atomic.CompareAndSwapUint64(p.env.visibleSeqNum, curSeqNum, newSeqNum) {
// We successfully published t's sequence number.
break
}
}
t.commit.Done()
}
}
执行到 publish 方法,说明当前 batch b 已经被 appy 到 Memtable 中了,这里先将其标记为 applied 状态,然后从队列取出队头 batch,注意:1. 取出的 batch 有可能是当前线程对应的 batch,也有可能是其他线程的 batch;2. 如果队头 batch 并未 apply,则其并不会出队列,同时返回 nil 。如果返回的是 nil,则调用 commit.Wait 等待 SeqNum 发布和 Wal 落盘,否则,通过循环 + CAS 的方式更新整个 DB 的 visibleSeqNum。
我们看下第二层 for 循环中更新 visibleSeqNum 的逻辑,首先通过原子操作取出 visibleSeqNum,然后根据 t 计算新的 SeqNum,如果新的 SeqNum < visibleSeqNum,说明有排在 t 后面的 batch 已经被其他线程 publish 了,那么 t 也就相当于 publish 了,直接退出循环,否则更新 visibleSeqNum。t 成功 publish 后调用 t.commit 将计数减一,而后回到第一层循环继续消费 pengding 队列。
可以看到,publish 设计得比较有意思,支持多个消费者同时消费 pending 队列,而且每个线程可以消费其他线程的 batch。这样做的好处是每个线程不必等着处理自己的 batch,多个线程可以接连不断地消费 pending 队列并独立 publish batch,充分利用多核优势提升性能。
到此,pipeline 的三个阶段便分析完成,整个写入流程也就结束了。下一章将继续补充写入路径上对 large batch 的特殊处理,以及详细讲解 makeRoomForWrite 的执行逻辑。
总结
本章从源码角度出发,按照源码执行流程,对写入流程进行了剖析并着重讲解了 Pipeline 的三个阶段。Pebble 利用 Pipeline、异步处理、CAS 无锁编程、多线程等多种技术手段打造出了高效的写入性能。本章并未覆盖到所有细节点,欢迎感兴趣的同学多多交流。