Compaction 策略 - Size-Tiered
开篇
本系列文章主要介绍 LSM-Tree 中非常重要的技术点 – Compaction。理解 Compaction 的作用及工作机制,对基于 LSM-Tree 类型的数据库开发或者调优有极大的益处。本系列文章将结合业界大佬的博文和笔者自己的思考总结对 compaction 运作机制进行详细讨论,本文为第一篇,主要介绍 Compaction 的定义、由来、工作原理等,同时也会介绍 compaction 的其中一种策略 – Size-Tiered。
Compaction
compaction 是什么?为什么需要 compaction?在回答这两个问题前,先简单介绍下 LSM-Tree (Log Structured Merge Tree)。LSM-Tree 设计的初衷是为了达到高效地写入及良好读取数据的目的,基于 LSM-Tree 的数据库写入更新都是先将数据写入到内存中的 memtable,当其达到一定阈值后,转变为 immutable memtable,然后刷到磁盘文件 sst(sorted string table)中,sst 是不可修改的,数据的更新和删除都是以写入新记录的形式呈现。数据在文件中是按 key 有序组织的,利于高效地查询和后续合并。
随着数据的不断写入和更新,sst 的数量会不断增加,进而会出现两个问题:1. sst 中可能存在修改前的老数据和已经删除的数据,这些无用数据会占用存储空间,造成资源浪费;2. 由于 sst 越来越多,数据分散在多个文件,读取时,可能会访问多个文件,导致读性能下降。对于上述问题,需要一些机制去解决,这种机制就称为 compaction,compaction 的目的是将多个 sst 合并成一个,在合并的同时将无用的数据清理掉,合并成的新文件也是按 key 排序的。可以看到,通过 compaction,上述很好的解决上述问题。
现在,我们知道什么是 compaction 及 compaction 的作用了。但是 compaction 应该以什么策略来选择需要合并的 sst,以及策略产生效果如何?进入本文的主题 Size-Tiered Compaction。
Size-Tiered Compaction
从名称可以看出,这种策略和大小有关,没错,Size-Tiered Compaction Strategy (STCS) 的思路就是将大小相近的 sst merge 成一个新文件。如下图:
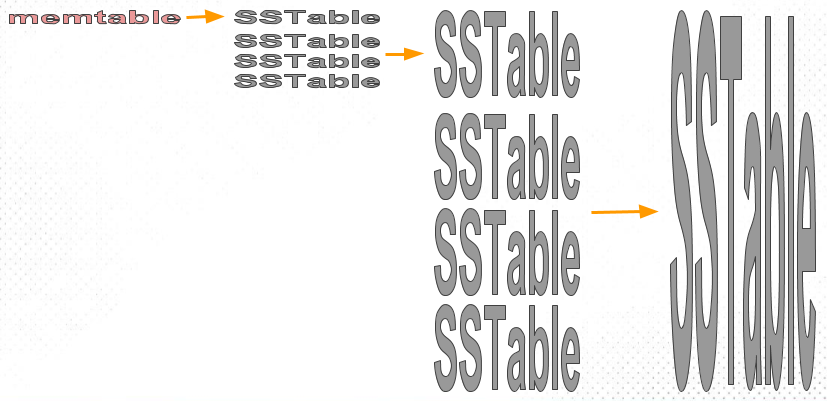
memtable 逐步刷入到磁盘 sst,刚开始 sst 都是小文件,随着小文件越来越多,当数据量达到一定阈值时,STCS 策略会将这些小文件 compaction 成一个中等大小的新文件。同样的道理,当中等文件数量达到一定阈值,这些文件将被 compaction 成大文件,这种方式不断递归,会持续生成越来越大的文件。
总的来说,STCS 就是将 sst 按大小分类,相似大小的 sst 分在同一类,然后将多个同类的 sst 合并到下一个类别。通过这种方式,可以有效减少 sst 的数量。由于 STCS 策略比较简单,同一份在数据 compaction 期间拷贝的次数相对较少,即写入放大相对小(和其他策略的 compaction 对比,在下章介绍),很多基于 LSM-Tree 的系统将其作为默认的 compaction 策略,如 Lucene、Cassandra、Scylla 等。
STCS 逻辑简单、写入放大低,但是它也有很大的缺陷 – 空间放大。其实也存在较大的读放大,这个放在下章介绍。
空间放大(Space Amplification)
空间放大指的是 compaction 的过程中,会导致数据膨胀,需要比原始数据更大的存储空间。对于机械硬盘来说,由于价格便宜,空间放大产生的代价相对可控。当时现在最主流的磁盘是 SSD(固态硬盘),SSD 的性能比机械硬盘好很多,但是价格也贵得多,因此,对于跑在 SSD 上的系统,空间放大无疑会带来很大的成本开销。
为了证明 STCS 带来的空间放大问题,Scylla 官方做了两个实验,我们一起来看看。
实验 1
该实验采用只写的方式向 Scylla 单节点持续写入一共 9GB(磁盘表现) 的数据,实验理想情况下应该看到磁盘空间使用按时间呈直线上涨的趋势图,但是结果如下:
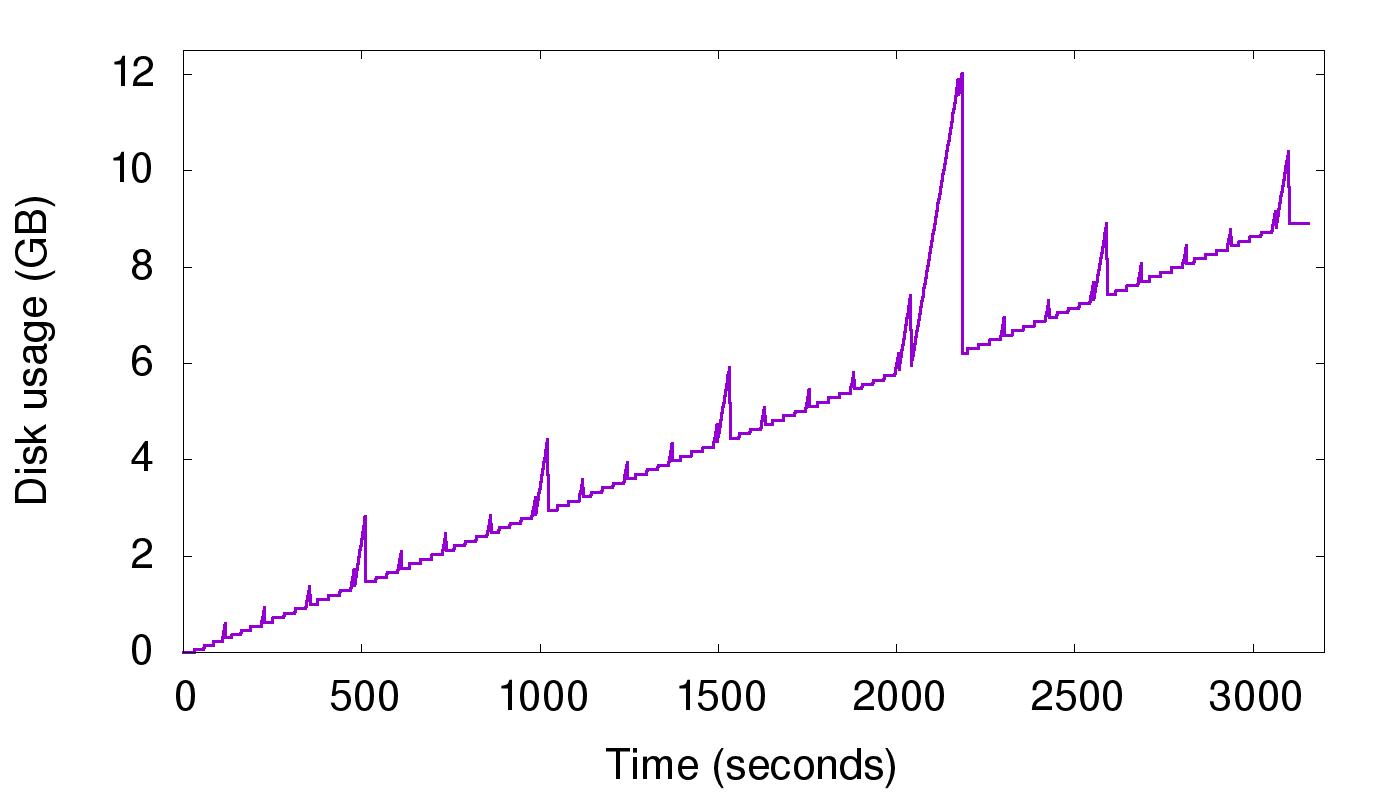
从上图可以看到,由于 compaction 带来的空间放大,会出现很多毛刺。刚开始毛刺比较小,是因为刚开始都是小文件,慢慢产生很多中等文件,再产生大文件,最后会产生超大文件,在 2000 时间点时,这些超大文件触发完全 compaction,磁盘使用几乎是当前数据的两倍。
那么为什么会产生空间放大呢?compaction 的过程中,参与 compaction 的 sst 不能立马删除,直到新生成的 sst 写入完毕,这里其实还有一个原因,如果老的 sst 有读操作,由于文件还被引用,也是不能立即删除的。因此,在 compaction 的过程中,磁盘上新老文件共存,产生临时空间放大。即使这种空间放大是临时的,但是对于系统来说,不得不使用比实际数据量更大的磁盘空间,以保证 compaction 正常执行,这产生的代价很昂贵。
本实验假设一直写入的数据不重复,空间放大最坏情况下为 2。这种情况还能接受,但是实际上,还会有更糟糕的情况,我们来看下 Scylla 官方做的第二个实验。
实验 2
这个实验的做法是,刚开始写入一定的数据量触发 flush,产生第一个 sst,随后,继续按照这个数据量重复写数据。当磁盘文件个数达到 4 (Scylla 默认触发条件)个时,触发 compaction,compaction 的过程中产生的最大空间放大为 5,因为会存在 5 份数据相同的文件(4个老文件,1个新文件)。但是随着写入的继续,实际情况可能更糟糕,因为同一份数据可能不仅在当前最大级别的 4 个文件中,还可能存在在更个更低级别的文件中,每个文件都是同一份数据的 copy,因此实际上存在多少文件就有多个的空间放大。我们来看下实现的结果:
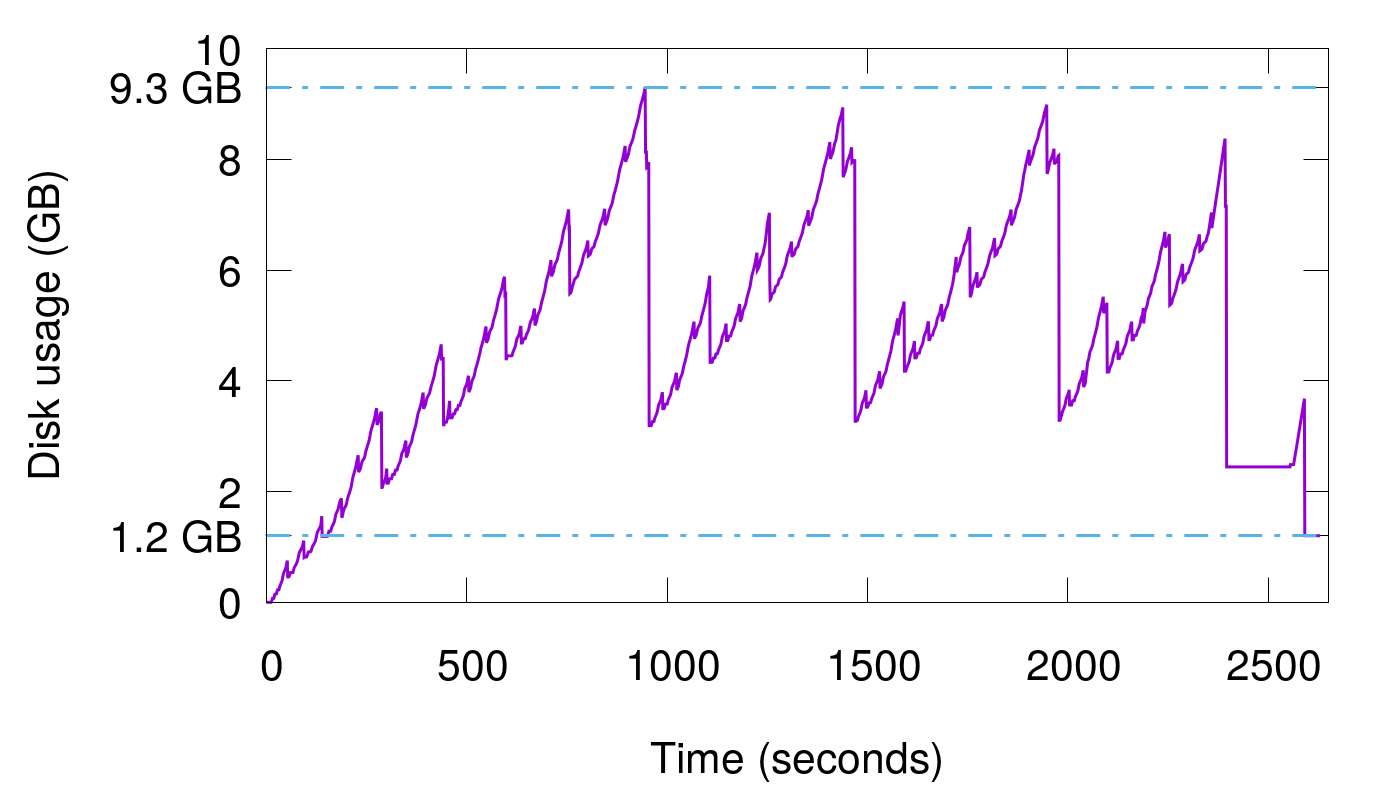
这是持续写入了 15 次相同数据的结果,可以看到最终的实际数据量是 1.2 GB,但是在中途 compaction 的过程中,最大的磁盘空间占用达到了 9.3 GB,空间放大接近惊人的 8 倍。因此,在数据覆盖写的场景下,空间放大极其严重。
通过 Scylla 官方的这两个实验,对于覆盖写较少的场景,STCT 的空间放大尚可接受;但是对于覆盖写频繁的场景,STCT 便不再是一个很好的选择。因此,针对空间放大问题,业界大佬们有提出了新的解决方案,我们下章介绍。
总结
本文主要介绍了 compaction 的定义及作用,并介绍了最简单的一种 compaction 策略 – Size-Tiered。分析了 STCT 的优缺点,并结合 Scylla 官方的实验结果,直观展示了 STCT 空间放大的缺陷。通过对 compaction 策略的分析,对于我们开发或者理解基于 LSM-Tree 的数据库系统有很大帮助,下章将继续介绍另一种 compaction 方案。