lucene 编码技术 - DirectWriter
DirectWriter 这个类的主要作用是将 long[] 型数据集编码存储到 byte[] 中,其实现充分考虑压缩比和性能因素。
编码原理
DirectWriter 使用的是固定位编码方式,即数据集中的所有元数均按照相同的固定位编码到 byte 数组。固定位的值 bitPerValue 只支持下面几种:
static final int[] SUPPORTED_BITS_PER_VALUE =
new int[] {1, 2, 4, 8, 12, 16, 20, 24, 28, 32, 40, 48, 56, 64};
至于 bitPerValue 为什么只支持上述 SUPPORTED_BITS_PER_VALUE 中的值,后面会详细分析。
bitPerValue
bitPerValue 即每个 value 所需要的 bit 位数,数据集中的所有数值统一按照 bitPerValue 来编码。那么对于一个数据集,如何确定其对应 bitPerValue 的值呢?很明显,bitPerValue 要能够编码数据集中任意值,必须以数据集中最大值来计算位数。举个栗子,有如下 long 数组:
long []values = {6, 2, 110};
我们用二进制来表示每个 value,如下:
| value | binary |
|---|---|
| 6 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000110 |
| 2 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000010 |
| 110 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 01101110 |
可以看出 6 有三位有效位(去掉前导 0),2 有两位有效位,110 有七位有效位。所以对于该数据集,bitPerValue 应该取值为 7。
上面计算出了数据集的 bitPerValue,那么又出现一个问题,因为 bitPerValue 的值 7 不在 SUPPORTED_BITS_PER_VALUE 中,那又该如何处理呢?这里结合源码来看看。
private static int roundBits(int bitsRequired) {
int index = Arrays.binarySearch(SUPPORTED_BITS_PER_VALUE, bitsRequired);
if (index < 0) {
return SUPPORTED_BITS_PER_VALUE[-index - 1];
} else {
return bitsRequired;
}
}
DirectWriter 提供了一个方法 roundBits,它可以根据 bitsRequired 的值从 SUPPORTED_BITS_PER_VALUE 中选取合适的值作为最终的 bitsRequired。逻辑很简单,因为 SUPPORTED_BITS_PER_VALUE 是有序数组,可以使用二分查找判断 bitsRequired 是否在数组中,如果在则直接返回 bitsRequired;如果不在,binarySearch 返回的值是 bitsRequired 插入点(第一个大于 bitsRequired 的索引位置)的负值,最终返回的就是第一个大于 bitsRequired 的数组元素。
所以,这里 bitPerValue 为 7 时,会从 SUPPORTED_BITS_PER_VALUE 中选取 8 作为其最终值。那编码后字节数组如下:
|- 2 -|- 6 -|- 110 -|
|00000110|00000010|01101110|
数据集编码后占用 3 bytes,而之前占用 24 bytes,压缩了 8 倍。
上面讲完了 DirectWriter 的编码原理,可以看到其编码原理还是很简单的,比较核心的一点就是 SUPPORTED_BITS_PER_VALUE 的选取,这也是本篇本章讨论的重点,下面会详细分析为什么 bitPerValue 只能选取 SUPPORTED_BITS_PER_VALUE 中的值。
SUPPORTED_BITS_PER_VALUE
本节我们举几个栗子来说明 SUPPORTED_BITS_PER_VALUE 的作用。
栗子1:
假设有如下数据集1:
long []values = {117, 110, 99};
上述数据的二进制表示如下:
| value | binary |
|---|---|
| 117 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 01110101 |
| 110 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 01101110 |
| 99 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 01100011 |
最大值为 117,计算出 bitPerValue 为 7。假设我们不用 SUPPORTED_BITS_PER_VALUE,直接按 7 bits 来编码数据集,则编码后的字节数组如下:
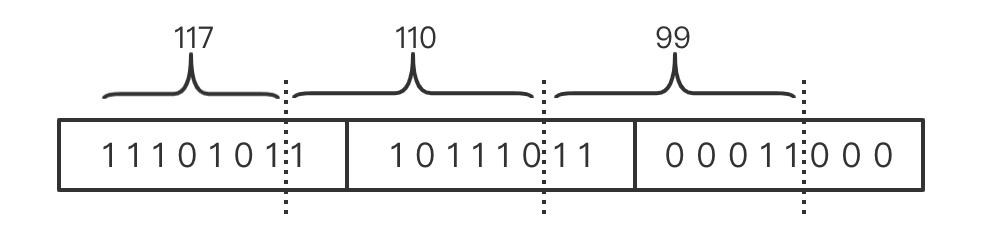
从上图可以看到,除了第一个数只存入到一个字节中,其他两个数都存入到了两个字节。这也就意味着,要操作两个 byte 才能将 110 和 99 写入或读出。如果使用 SUPPORTED_BITS_PER_VALUE,那么将按 8 bits 来编码数据集,编码后的字节数组如下:
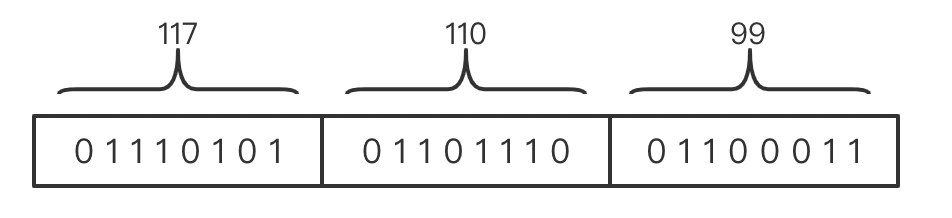
可以看到每个字节存一个数,那么在写入和读取时,都分别操作一个 byte 就可以了,相对上面 7 bits 的方式有更高的性能优势。
同理,对于 SUPPORTED_BITS_PER_VALUE 中的 16、24、32、40、48、56、64 这些 8 的倍数值,起到的效果和上述类似;1、2、4 这三个值也容易理解,因为它们都能整除 8 ,所以一个 byte 可以存放整数个位数为 1 或 2 或 4 的值,不会出现跨 byte 的情况 。但是对于 12、20、28 这三个值如何理解呢?为了解释这个问题,我们再举一个栗子:
假设有数据集2:
long []values = {309, 36, 293, 108};
上述数据的二进制表示如下:
| value | binary |
|---|---|
| 309 | 00000000 00000000 00000000 00000000 00000000 00000000 00000001 00110101 |
| 36 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00100100 |
| 293 | 00000000 00000000 00000000 00000000 00000000 00000000 00000001 00100101 |
| 108 | 00000000 00000000 00000000 00000000 00000000 00000000 00000000 01101100 |
最大值 309,bitPerValue 为 9,如果我们按 9 bits 来编码数据集,则编码后的字节数组如下:

由于 9 bits 大于一个字节,每个数值都必须用 2 个 byte 来存储,跨字节这个问题无法避免。我们再观察上面几个数的存储还有其他弊端没?可以看到,除了第一个数的起始偏移是按字节对齐的,其他数的起始偏移都没按字节对齐,这就意味着如果要读取这些数,首先要定位到起始偏移所在的 byte,然后再定位 byte 内的偏移,因此定位起始偏移的开销相对较大。
既然这样,我们直接用 16 bits 来编码是否更好呢?用 16 bits 来存储确实性能会更好,因为计算起始偏移的开销更低了。但是压缩率又变差了,16 bits 编码需要 8 bytes,而 9 bits 编码只需要 5 bytes。 那我们有没有折中的方案呢,既能够取得较好的压缩率,又有很好的读写性能。
我们看看使用 SUPPORTED_BITS_PER_VALUE 后的效果,如果是 SUPPORTED_BITS_PER_VALUE,那么便会用 12 bits 来编码,编码后的 byte 数组如下:

从上图可以看出,使用 12 bits 编码后,每两个数中有一个数计算起始偏移时需要计算 byte 内偏移,而使用 9 bits 编码是每 8 个数中有 7 个需要计算 byte 内偏移。所以相对 9 bits 编码在这块的开销比为 1/2 : 7/8 = 4 : 7,而压缩比为 5 : 6。因此使用 12 bits 编码既能取得接近 9 bits 相近的压缩率,还能有更好的性能。
同理,20、28 bits 编码解决的问题和 12 bits 类似,这里不在赘述。
总结
本文结合源码和例子详细分析了 DirectWriter 的编码原理,特别对 SUPPORTED_BITS_PER_VALUE 的作用进行了深入分析。DirectWriter 在 lucene 中多处被使用,大家如果想了解更细节地实现可以查看相关源码。