lucene DocValues之NumericDocValues
其实多年前就已经研究过这块内容,但是久了不看有所遗忘,正好近期工作内容和 lucene 的 DocValues (即列存)打交道比较频繁,顺便记录分享相关内容。本章先介绍最简单的一种 DocValues – NumericDocValues,后续会分享其他类型 DocValues 的相关内容。本系列文章都是基于 lucene 版本 9.5.0 来讲解。
文件 layout
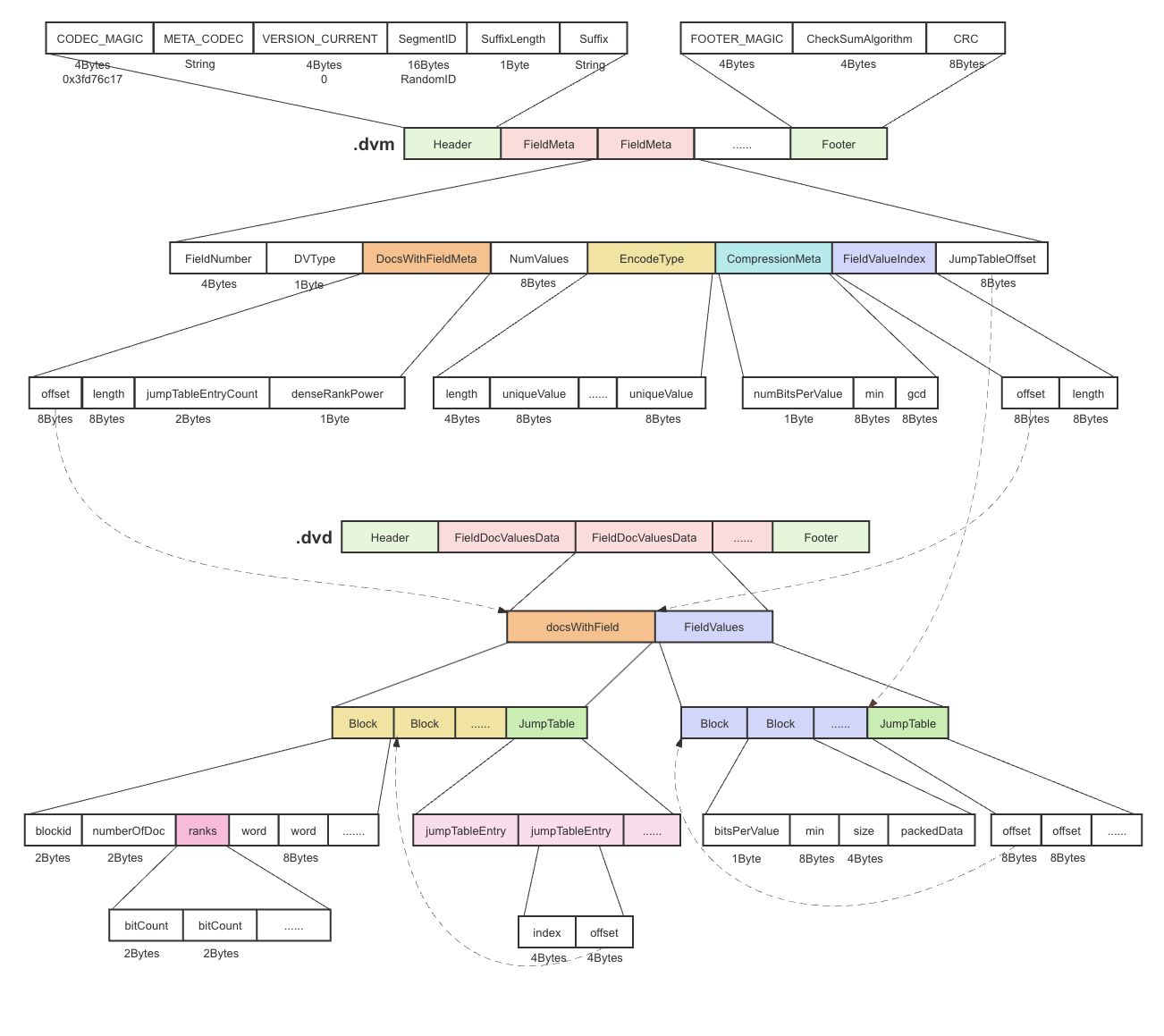
先上图,一图胜千言。
写文件入口: 点击进入
上图代表了整个 NumericDocValues 的文件 layout,主要包括两个文件:.dvm 和 .dvd,下面分别进行介绍。
dvm
dvm 是 dvd 的元数据,主要由三部分构成:Header、FieldMeta、Footer。
Header
固定内容,包含文件的编码信息、版本等,见上图。
FieldMeta
核心部分,存储每个 Field 相关的 meta 数据。每个 Field 对应一个 FieldMeta,FieldMeta 构成部分如下:
FieldNumber
Field 编号。
DVType
字段 DocValues 类型,这里存的是一个枚举值,NumericDocValues 对应的类型值为 0。
DocsWithFieldMeta
这个部分是数据文件 dvd 中 docsWithField 的元数据,docsWithField 在下文介绍。DocsWithFieldMeta 由下面部分构成:
offset & length
docsWithField 在 dvd 中的偏移和长度。如果所有文档都包含该 Field,那么 offset 值为 -2,length 值为 0;如果所有文档都不包含该Field,那么 offset 值为 -1,length 值为 0.
jumpTableEntryCount & denseRankPower
这两个变量和关键数据结构
IndexedDISI相关,介绍IndexedDISI后再补充。如果所有文档都包含或者都不包含该 Field,那么这两个变量的值都为 -1.
NumValues
该 Field 在 segment 中的数量,由于 NumericDocValues 类型的字段是单值的,因此 NumValues 和包含该字段的文档个数相同。
EncodeType
Field values 在 dvd 中存储的编码类型,分情况讨论:
情况1:所有 values 都相同
这种情况下,EncodeType 值为 -1。由于所有值都相同,不必将 values 存入到 dvd 中,dvm 中会存一个 min(见下文),代表所有相同的 value。
情况2:字典编码
当 Field values 的基数满足一定条件时,采用字典编码,在 dvd 中存储 values 的编码值。是否采用字典编码的判断条件如下:
if (uniqueValues != null && uniqueValues.size() > 1 && DirectWriter.unsignedBitsRequired(uniqueValues.size() - 1) < DirectWriter.unsignedBitsRequired((max - min) / gcd))也就是说当字典编码的最大值所需的位数比
差值&最大公约数所需位数更少时,则使用字典编码。差值&最大公约数编码可以看 这篇文章 。这种情况下 EncodeType 为一个复合结构,如下所示:
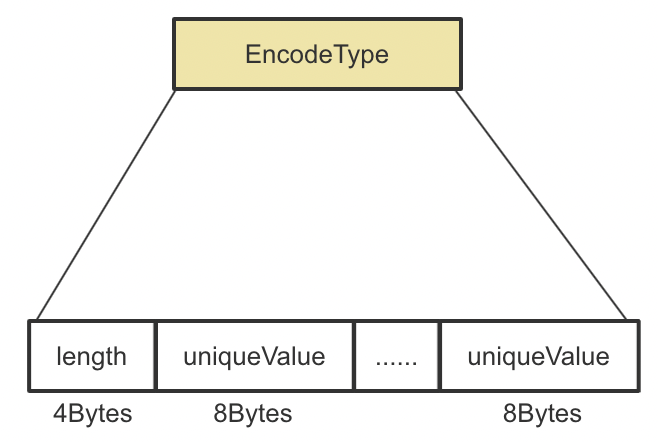
length 表示字段 uniqueValue 的个数,后面跟上排序后的 uniqueValues。比如字段值为 [2, 3, 9, 6, -1, 6, 2],那么这里存储的内容为:5 |-1|2|3|6|9.
情况3:差值&最大公约数编码
这种情况下,字段的每个 value 将按位数为 DirectWriter.unsignedBitsRequired((max - min) / gcd)) 存储。同时为了提高压缩效率又将 Field values 的存储方式分为 SingleBlock 和 MultiBlock。如果是 SingleBlock,EncodeType 的值为 -1(和情况1相同,后面会通过 numBitsPerValue 区分);如果是 MultiBlock,EncodeType 的值为 -16。
EncodingMeta
差值&最大公约数编码所需的元数据,编码公式为 $(v-min)/gcd$,因此元数据包含 min、gcd,当然还需要编码需要的位数 numBitsPerValue,当 EncodeType 为情况1时,numBitsPerValue 为 0。注意,这里 min 还有一个作用是在 EncodeType 为情况1时,代表所有 values 的值。
FieldValuesIndex
表示 FieldValues 在 dvd 中的偏移 offset 和长度 length。
JumpTableOffset
FieldValues 按 Block 存储,JumpTable 可以加速 Block 的定位,JumpTableOffset 表示 JumpTable 在 dvd 中的偏移。
Footer
存校验码,用于校验文件内容,见上图。
dvd
dvd 由三大部分组成:Header、FieldDocValuesData、Footer。本节主要讲解 FieldDocValuesData 部分,Header、Footer 忽略。
FieldDocValuesData
Field 对应的 docValues 数据,包含两部分:docsWithField 和 FieldValues。
docsWithField
包含该 Field 的所有 docs,作用是查询时确定查询的 doc 是否存在以及定位 doc 在 segment 中的偏移。当 segment 中所有 docs 都包含或者都不包含该 Field 时,docsWithField 部分不需要存储。
如果 docsWithField 存在,则存储它的数据结构为 IndexedDISI,这个数据结构还是比较有意思,上图画的只是其中一种情况,下一篇文章会详细介绍。
FieldValues
该 Field 对应的所有 values。FieldValues 的存储结构得分情况讨论,对应 dvm 的 EncodeType。
情况1:所有 values 都相同
这种情况下,values 不用存储,即 FieldValues 不存在。
情况2:字典编码
这种情况下,dvd 中不用存储 value 的原始值,而是存储 value 的字典映射值,比如原始值为 [6, 9, 5, 8, 5, 6, 7],那么字典映射表如下:
5 --> 0 6 --> 1 7 --> 2 8 --> 3 9 --> 4那么存到 dvd 中的 values 便为 [1, 4, 0, 3, 0, 1, 2],然后用 DirectWriter 编码存储。DirectWriter 原理请看 这篇文章 。
情况3:差值&最大公约数编码
在讲 dvm 时,已经大体提过,这种情况会分为两种存储方式:SingleBlock 和 MultiBlock,采用这种编码,每个 value 所需的位数为 DirectWriter.unsignedBitsRequired((max - min) / gcd)),因此,当 max - min 越小,所需位数更少。当采用 MultiBlock 的空间开销能节约 10% 以上时,则使用 MultiBlock ,否则使用 SingleBlock。判断条件如下:
// we do blocks if that appears to save 10+% storage doBlocks = minMax.spaceInBits > 0 && (double) blockMinMax.spaceInBits / minMax.spaceInBits <= 0.9;SingleBlock 比较简单,代码见 点击进入 。另外情况 2 也是使用的 SingleBlock 存储的。
MultiBlock 存储如下:
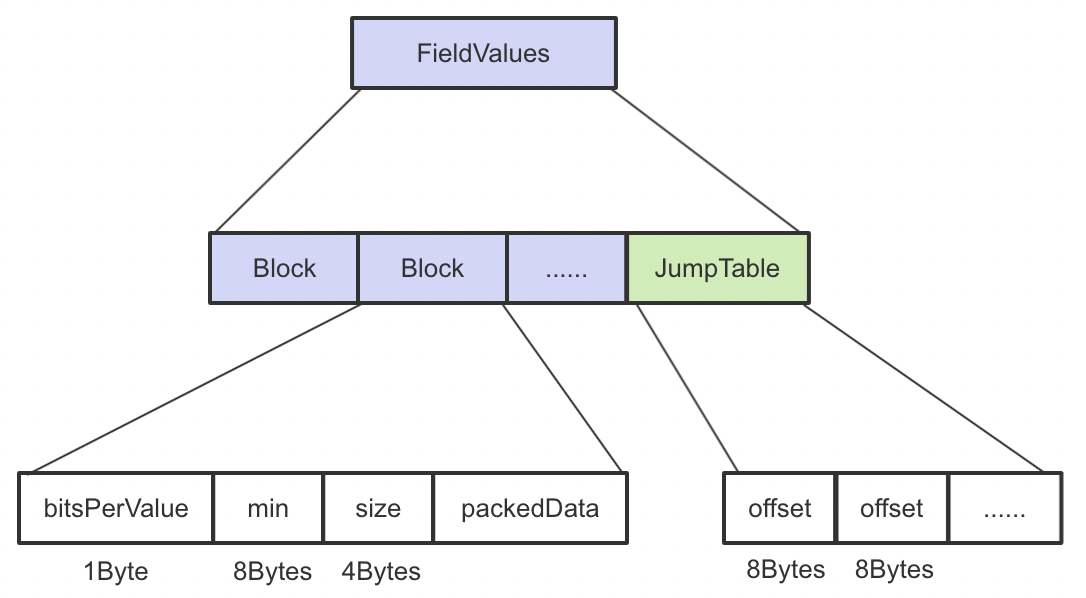
每 16384 个 value 切成一个 Block,由于每个 Block 中 bitPerValue 和 min 不一定相同,因此每个 Block 都会存自己的 bitsPerValue 和 min,packedData 即压缩后的数据,size 表示 packedData 的大小。在查询时,为了加快 Block 的定位,会使用 JumpTable 存储每个 Block 的偏移。
总结
本章讲解了 NumericDocValues 的文件 layout,至于 layout 的生成过程可以看本文提供的源码链接,关键地方笔者都加有注释。下一章将会讲解 NumericDocValues 的读取流程,同时会着重介绍数据结构 IndexedDISI。