DuckDB:高性能并行分组聚合
分组聚合对于 OLAP 数据库来说是一个核心的分析算子,常常用于对大规模数据集做分组统计。针对这样一个重要算子,DuckDB 也是做了深度地优化。本文将结合 DuckDB 相关技术资料来分析其背后的优化原理。
Introduction
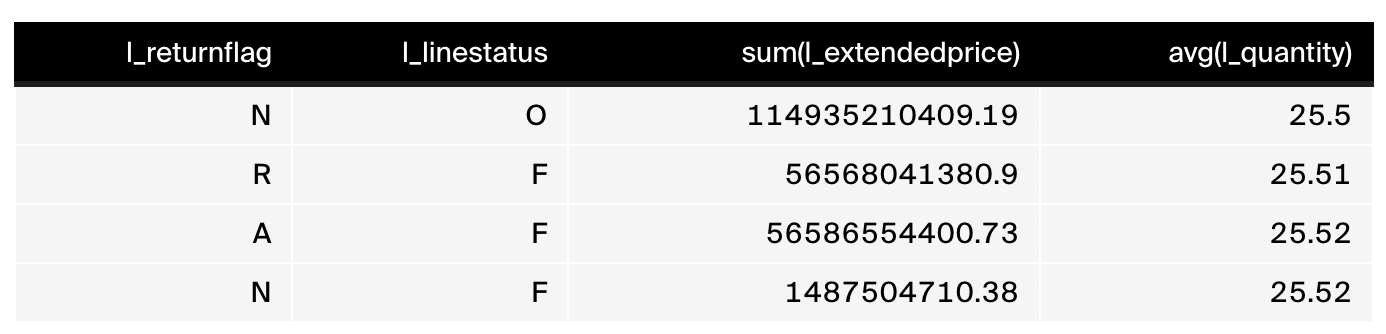
Group By的作用是对按照分组字段,对数据行进行分组聚合,返回所有分组字段的值及其聚合值。举个栗子:
SELECT
l_returnflag,
l_linestatus,
sum(l_extendedprice),
avg(l_quantity)
FROM
lineitem
GROUP BY
l_returnflag,
l_linestatus;
这个栗子中对表中字段 l_returnflag 和 l_linestatus 做分组。这两个分组字段的所有组合值构成不同的分组。Group By 将数据行放到对应的分组中,从而形成不同的分组数据。投影往往会带上分组字段和其他聚合算子,达到分组聚合的统计目的。上述 SQL 语句的聚合结果如下:
那对于 Group By 算子,DuckDB 的查询引擎是如何工作的呢?我们可以先来设想下,假设要聚合的数据表是按照分组字段排好序的,那对于这种情况就好办了。只需要顺序 SCAN 每一行,读取每行分组字段的组合值,然后上前一行的值做比较,如果一样,那么就将它们划到同一组。否则,将当前行划到新组,不断重复上述步骤直到所有行 SCAN 完毕。可以看出在数据天然按照分组字段有序的情况下,只需一次 SCAN 便能得到分组结果,时间复杂度为 $O(n)$。
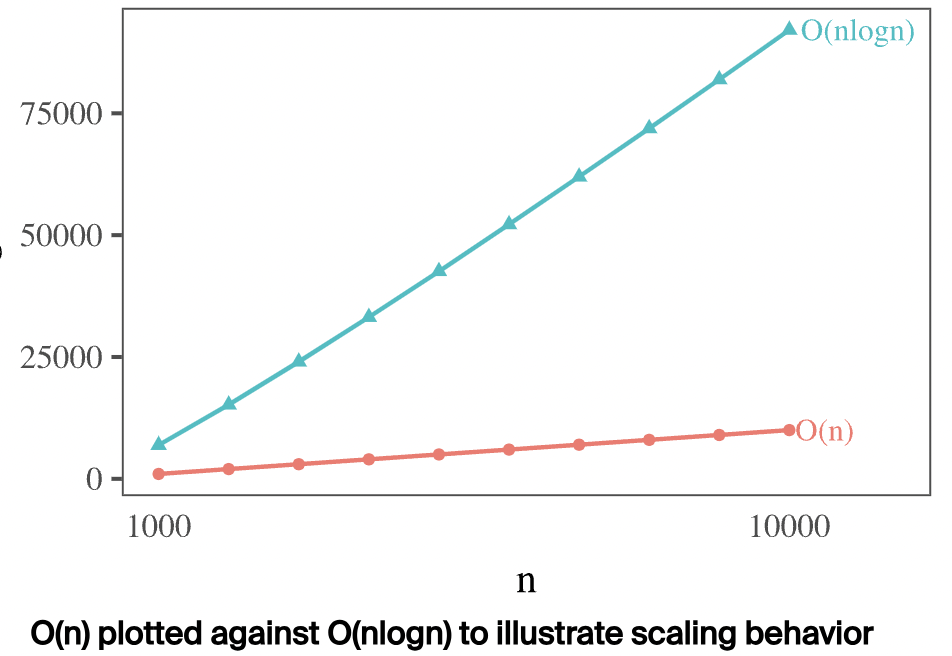
上述分组方式称为 Sorted Aggregation,那对于数据不是按照分组字段有序的情况怎么办呢?一种自然的想法就是首先对输入的表数据按照分组字段排序,然后再使用 Sorted Aggregation 做分组。整体来讲,一般排序的时间复杂度为 $O(nlogn)$,$n$ 为数据表的行数,这个开销相对而言还是比较大的。那么接下来看下还有没有更好的方式来分组。
Hash Aggregation
Hash Aggregation 其实也是一种常见的分组聚合算法。其核心思想就是利用 Hash Table 存储不同分组的聚合数据,类似于 java 中的 HashMap,key 为分组字段的组合值,value 为聚合值。我们知道,Hash Table 的查找时间复杂度为 $O(1)$,那么将 $n$ 行数据加入到 Hash Table 中,时间复杂度为 $O(n)$,这比 $O(nlogn)$ 好太多了,尤其当数据量达到数十亿条时,这种差距更明显。如下图:
除了时间复杂度的优势外,对于排序来说,如果是内排,那么需要将涉及的所有数据都 Copy 到内存,内存开销较大。但是对于 Hash Table 来说,只需要存储所有分组信息即可,这个数据往往远低于原始表数据。
Collision Handling
上面把 Hash Aggregation 说得那么好,是不是它就真的那么完美呢?当然不是,众所周知,Hash Table 在构建的时候常常会遇到 Hash Collision 即哈希碰撞问题。当不同的分组数据哈希到同一个桶时,这时候便出现哈希碰撞问题,那么如何解决呢?
解决哈希碰撞问题主要有两种方式:拉链法 和 线性探测法。如果使用拉链法,那么每个哈希项其实是一个链表,哈希到同一桶的分组信息插入到同一个链表中,如下:
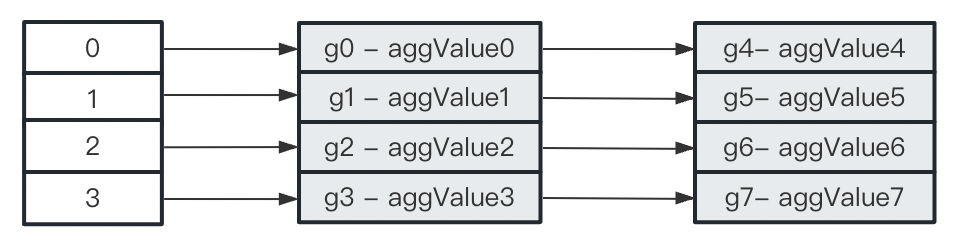
如果使用线性探测法,那么也是分组值做哈希,然后映射到对应的桶,如果当前桶有值且和当前分组值相等,那么我们更新聚合值;如果当前桶没有值,那么我们将分组信息直接填充到桶中;如果当前桶有值且和当前分组值不同,那么我们顺序往下找,直到找到分组值相同或者空桶为止。如下所示:
| bucket | Group Value | Aggregates |
|---|---|---|
| 0 | g0 | value0 |
| 1 | g1 | value1 |
| 2 | g2 | value2 |
| 3 | g3 | value3 |
| 4 | g7 | value7 |
| 5 | g5 | value5 |
| 6 | g6 | value6 |
| 7 | g4 | value4 |
理论上上述两种方式都能较好的处理哈希碰撞问题,但是从计算机硬件的角度来看,由于链表元素在内存中不连续,会带来很多随机访问,对现代硬件架构不友好。而线性探测法不用使用链表,底层的 Hash Table 一般采用数组结构,在内存中是连续的,且线性探测的过程也是顺序访问,根据局部性原理,大部分时候数据能在 CPU Cache 中命中,性能会得到极大提升。因此,DuckDB 选择线性探测处理哈希碰撞。
如果哈希碰撞的频率太高,那么 Hash Table 的查找时间复杂度降退化为 $O(n)$,这当然是不能接受的,问题的解决办法是,扩容 Hash Table,当 Hash Table 的装载因子超过一定阈值后触发扩容。举个栗子:
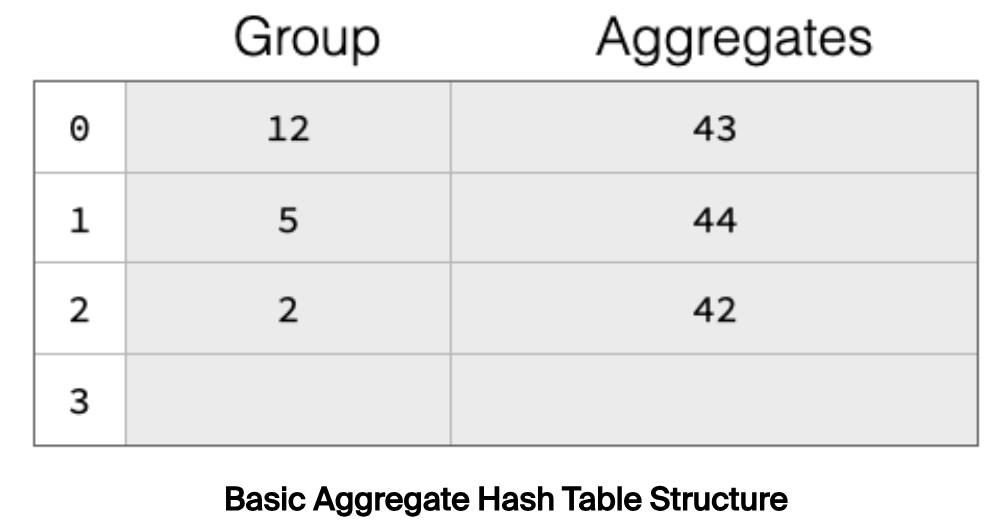
上述 Hash Table 有 4 个桶,已经有 3 个桶被占用,装载因子为 75%,将触发扩容。Hash Table 一旦扩容,那之前数据则需要 rehash 重新挪动位置。数据搬迁是个非常重的操作,开销较大,为了降低数据搬迁的开销,DuckDB 采用了一种称为 Two-Part Aggregate Hash Table 的结构,如下:
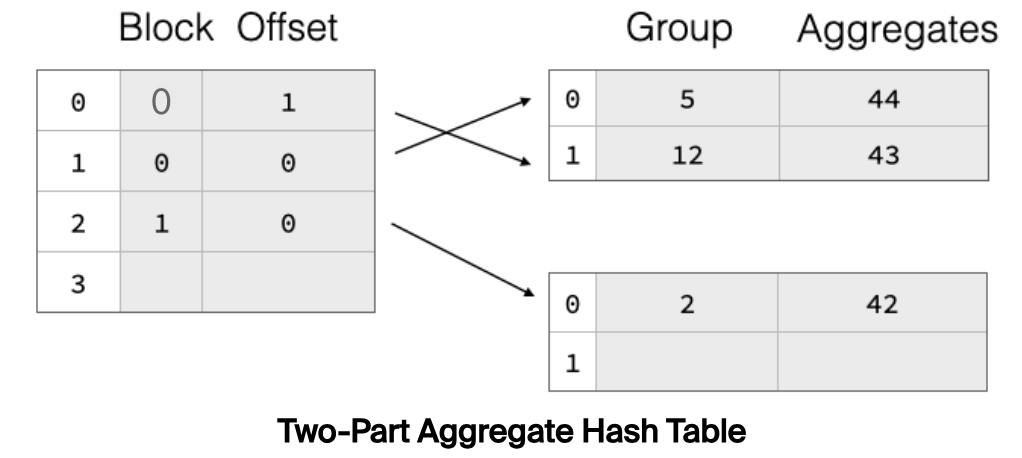
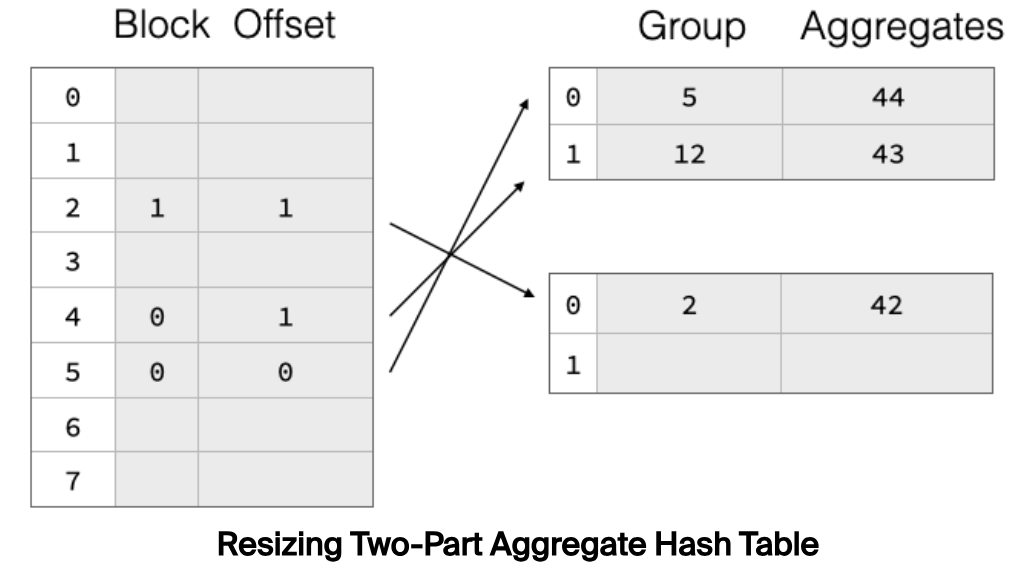
Hash Table 分成两部分,真实的分组数据放在右边部分,称为 payload blocks;左边部分存储每个分组数据的位置信息(包含 Block 和块内偏移)。扩容时,只需要读取右边的分组数据,rehash 定位到新桶,然后修改对应桶的位置信息指向对应的分组数据。如下所示:
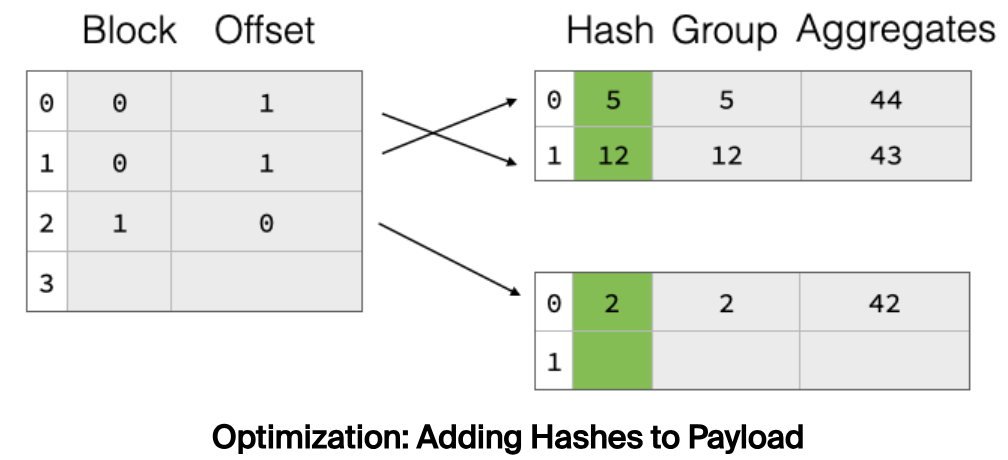
将所有的分组数据都做一遍 rehash 也是一个较大的开销,特别是对于字符串类型的数据来说,这个开销更明显。怎么解决这个问题呢?一个自然的想法就是用空间换时间,将 hash 值也存起来,那么下一次用的时候直接读取即可。DuckDB 就是这样做的,如下所示:
Two-Part Aggregate Hash Table 有没有什么明显的问题呢?进一步分析下,在线性探测的过程中,首先在左边部分获取到对应桶的地址信息,然后再去右边的 payload block 中读取数据。很明显,同一个 payload block 时内存连续的,如果在线性探测的过程中顺序读取的分组数据在同一个 payload block 中,大概率能够命中 CPU Cache。
但是,左边 Hash Table 中的地址是无序的,也就意味着在顺序 SCAN Hash Table 时读取的 payload block 是随机的。问题的解决办法是,在左边的 Hash Table 中也带上分组数据的原始 hash 值,如下:
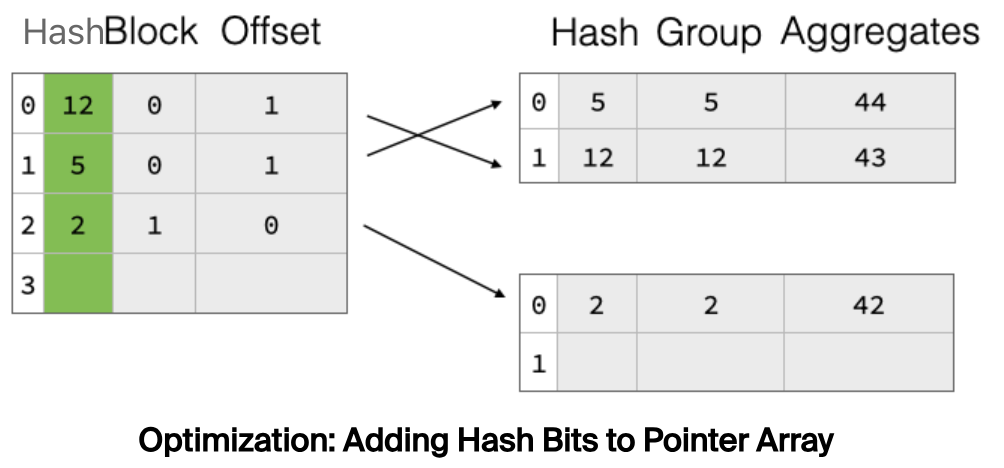
在线性探测时,首先对比当前分组的 hash 值和 Hash Table 中的 hash 值,如果相等,再通过地址找到对应的分组数据并和当前分组数据做比较。如果 hash 值不等,那么便可直接跳过当前桶,继续往下探测,从而减少了随机访问次数。
Parallel Aggregation
通过上面的设计,现在已经得到了一个高效的 Hash Table 。由于 Hash Table 不支持并发读写,不能充分发挥现代 CPU 并行处理能力。DuckDB 参考论文
Leis et al.
将原始表数据切分成多个 morsel,然后由多个线程独立处理其对应的 morsel 构建 local hash table,这一步可以达到并发。
如果两个分组的 hash 值不同,那么这两个分组值肯定不同。根据这一点,我们可以用分组的 hash 值将各个 Hash Table 切分成多个分区,相同 hash 值的数据分到相同的分区,如下:
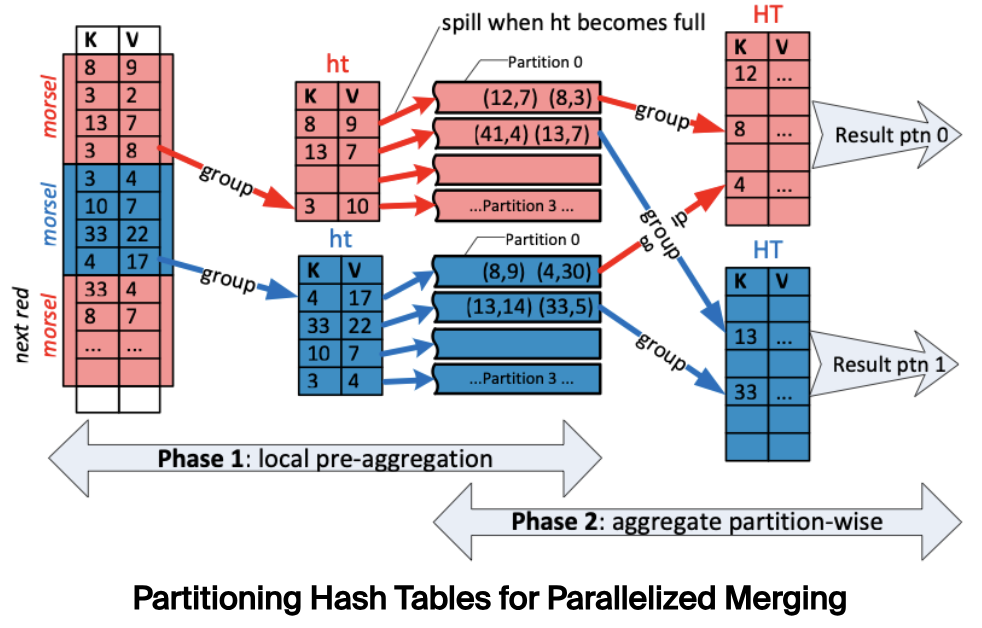
然后每个线程负责 reduce 对应的分区数据,生成新的 Hash Table 。由于最终合并出来的多个 Hash Table 间的分组值各不相同,因此将各自的输出结果简单整合起来就是最终的分组结果。
这个并行处理的方式下面这篇文章的思路类似,详细可以看这篇文章:
Experiment
DuckDB 通过下面三组数据分别对比了不同分析引擎的分组时延,如下:
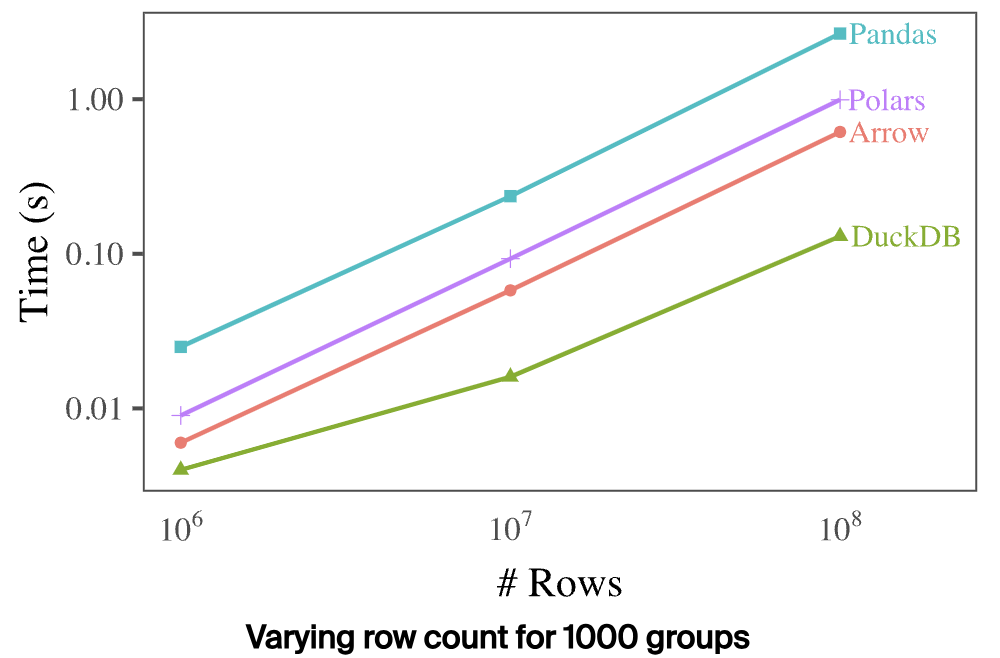
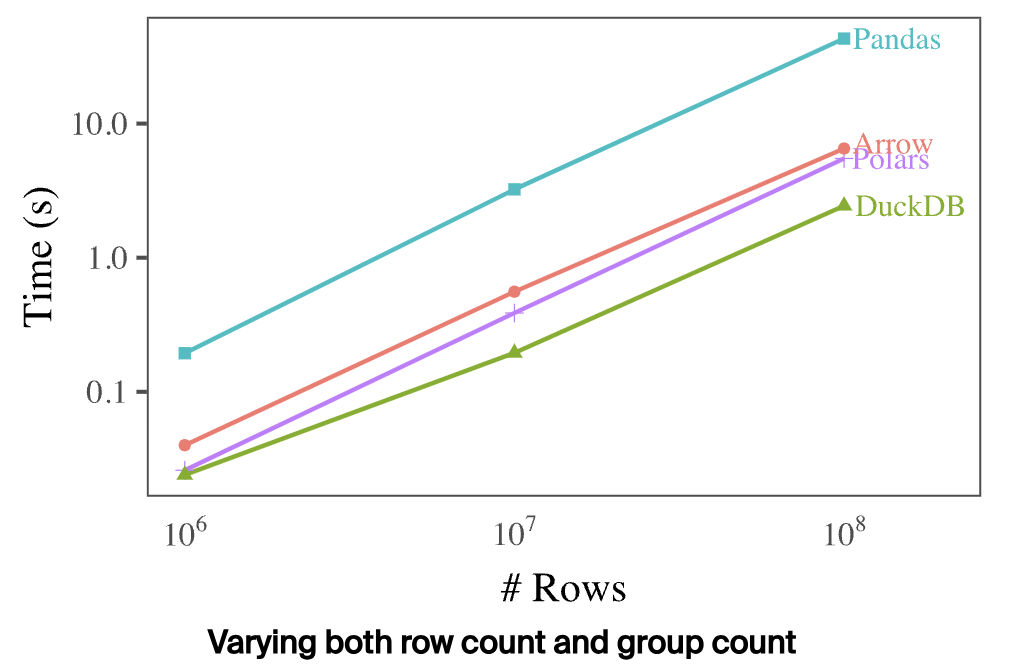
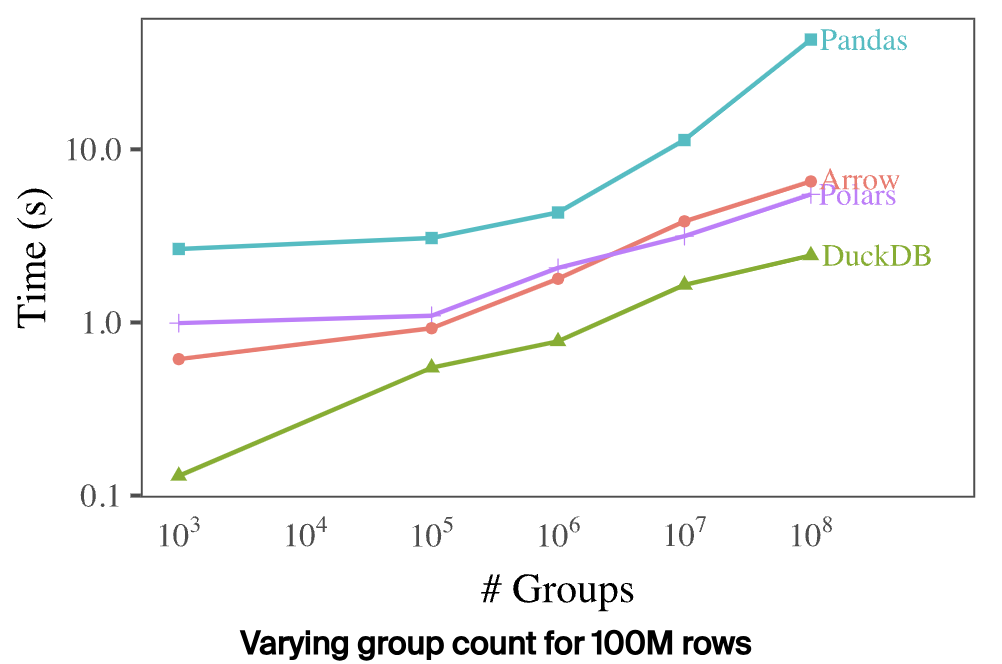
总的来看,DuckDB 在三种场景下,性能都远超其他引擎,看起来优化效果确实很牛。
Conclusion
Hash Table 在数据分析中应用十分广泛,对 Hash Table 的设计和优化做到极致是非常有必要的。DuckDB 作为一款性能出众的 OLAP 数据库,在这方面做了很多的工作,有机会拜读相关源码再继续补充分析。