WiscKey: Separating Keys from Values in SSD-Conscious Storage 论文解读
1 介绍
LSM-tree(Log-Structured Merge Tree)是一种常见的数据结构,其具备高效的写入性能和较好的查询能力,很多键值数据库选择这种结构来实现存储引擎,比如 RocksDB、LevelDB、HBase 等。
传统的机械硬盘 (HDDs) 随机 IO 速度比顺序 IO 慢了两个数量级以上,LSM-tree 先将数据缓存在内存中,然后再一把刷入磁盘形成 SST,天然地将随机 IO 转换成顺序 IO,恰好规避了 HDDs 的最大弊端。将 LSM-tree 应用在 HDDs 上能取得很好的效果。
为了平衡查询性能, LSM-tree 会在后台将磁盘上的 SST 排序合并在一起,一份数据在其生命周期内可能会被读取写入多次,会造成 IO 放大。随着现代存储设备的发展,固态硬盘(SSDs)使用越来越广泛,然而,SSDs 和 HDDs 本质上有很大的区别,主要表现为如下几点:
- 相比于 HDDs,SSDs 的随机 IO 性能和顺序 IO 性能的差异并没有那么大,LSM Tree 用磁盘带宽换取顺序写的收益表现得没那么明显
- SDD 内部具备并行访问能力,构建在 SSD 上的 LSM Tree 在设计上应该充分考虑并行性
- 大量的写入操作对 SSD 会造成磨损,因此 LSM Tree 的写入放大会减少设备的生命周期
基于上述背景,论文提出了一种称为 WiscKey 的键值存储,其实现了一种专门针对 SSD 的 LSM-tree。WiscKey 的核心思想是将 keys 和 values 分离,keys 存储到 LSM-tree,values 单独存储在日志文件中。
这种简单的技术有效地降低了写放大,由于 values 没有存储在 LSM-tree 中,那么 LSM-tree 的大小自然就减小了,也就意味着可以将更多 LSM-tree 的数据缓存在内存中,进一步提升查询性能。
另外,kv 分离也会带来一些弊端:
- kv 分离后,scan 的性能势必会受到影响,因为 values 并不是按照 keys 有序排列的,因此会带来很多的随机 IO
- WiscKey 需要通过 gc 来清理一些无用的 values,gc 会消耗系统资源,影响前台性能
- Kv 分离会来一致性问题
后面章节会介绍 WiscKey 是如何解决上述问题的。
2 Background and Motivation
LSM-tree 和 LevelDB 就不过多介绍了,整体架构如下:
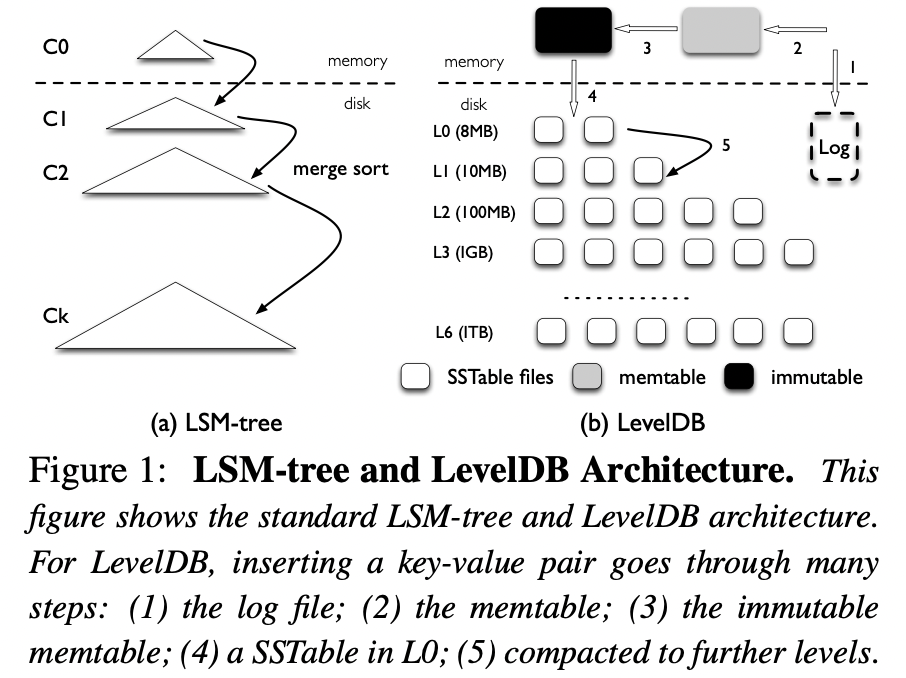
LSM-tree 主要问题就是读写放大,比如 LevelDB,我们来分析下 LevelDB 的读写放大问题。由于 LevelDB 的分层设计,$L_i$ 层的大小是 $L_{i-1}$ 的 10 倍,compaction 时,在最坏情况下,需要将 $L_{i-1}$ 层的 1 个文件和 $L_i$ 层的 10 文件做合并排序,然后再写入到 $L_i$ 层,所以相邻两层间的 compaction 写放大最高可以达到 10 倍。
对于大量数据集的写入,会不断新生新的文件,大部分文件经过 compaction,从 $L_0$ 迁移到 $L_6$ 写入放大超过 50 倍($L_1$ 到 $L_6$ 每层写入放大 10 倍)。
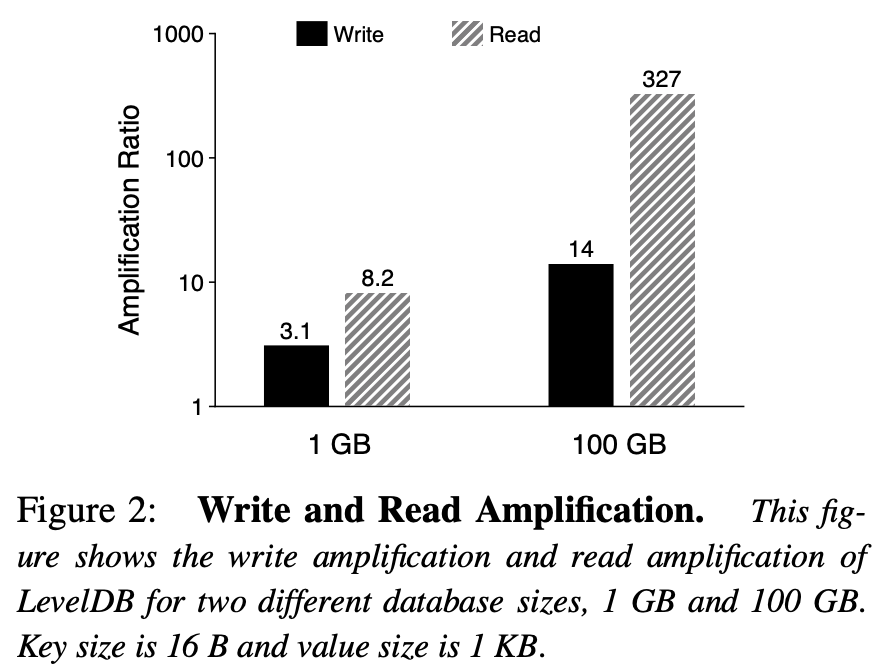
对于读操作,最坏情况下,需要查找所有层的文件,$L_0$ 层查找 8 个文件($L_0$ 层文件数据有重叠),其他 6 层各查找一个文件。而每个文件需要读取 16KB index block,4KB bloom filter block,4KB data block,一共 24KB,14 个文件一共 336KB。假设一个 key-value 键值对 1KB,那么读放大为 336。
总体来说,数据量越大,数据就容易往底层迁移,也就会造成更高的读写放大。如下:
3 WiscKey
WiscKey 的四个重要思想:
- Key 和 Value 分开存储,keys 依然存放在 LSM-tree,values 存放在 log 文件
- 由于 values 未按照 keys 的顺序存储,在范围查询时,会导致随机读,WiscKey 使用 SSD 的特性并行读取数据
- WiscKey 使用崩溃一致性(crash-consistency)和垃圾回收器(garbage- collection)来有效管理 log
- WiscKey 在保证一致性的前提下,去除 WAL 来优化性能
3.1 Design Goals
WiscKey 想达成的主要目标如下:
低写放大,写放大消耗大量的写带宽,降低 SSD 的使用寿命,降低写放大即可改善系统负载,还能提升 SSD 的使用寿命。因此,降低写放大至关重要。
低读放大,读放大会导致两个问题,第一,每次查询会到来多次读取操作,降低查询吞吐;第二,读放大会造成大量数据加载到内存,降低缓存效率,WiscKey 的目标是降低读放大,加快查询速度。
针对 SSD 优化,WiscKey 专门针对 SSD 的特性来做优化。特别是通过高效的顺序写和并发随机读来充分利用设备的带宽。
特性丰富的 API
Realistic key-value sizes,这里论文要表达的意思应该是 key 的长度有大有小,但是在实际情况下,key 的大小常常是比较小的。WiscKey 旨在针对大部分情况下的 key 大小提供高效的性能。
3.2 Key-Value Separation
LSM-tree 最主要的性能开销是 compaction,在 compaction 过程中,多个文件会被读到内存排序然后写回磁盘,这一系列的操作会影响到前台的性能。
WiscKey 将 keys 和 values 分离,compaction 只将 keys 读取到内存排序。因为 key 往往远小于 value,所以参与排序的数据量大大减少。在大 value 场景下,key-value 分离能够显著地降低写入放大。
假设 key 的大小为 16B,value 的大小为 1KB,key 在 LSM-tree 中的写放大为 10,value 的写放大为 1。那么 key-value 整体的写放大为 $(10 \times16+1024)/(16+1024)=1.14$。可以看到,通过 key-value 分离,写放大被有效的稀释掉了。
WiscKey 的架构如下:
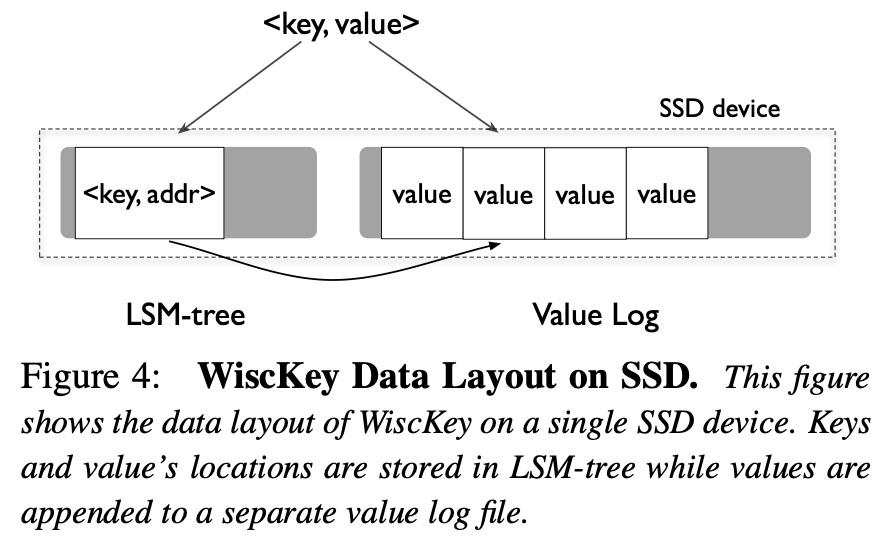
key 和 value 的地址存在 LSM-tree 中,value 存在日志文件 vlog 中。当插入一个 key-value 键值对时,先将 value 追加到 vlog,然后再将 key 和 value 的地址插入 LSM-tree。
删除也很简单,只需要将 key 从 LSM-tree 中删除(标删)即可。vlog 中所有有效值在 LSM-tree 中都有对应的 key,无效值将会被垃圾回收器清理掉。
WiscKey 在查询时,首先从 LSM-tree 中定位 key,进而得到 value 在 vlog 中的地址;然后,根据地址到 vlog 中获取 value。从流程上来分析,WiscKey 的查询性能应该弱于 LevelDB,因为多了一次查找 value 的 IO。
但是宏观来看,对于相同数据量, 一方面,WiscKey 的 LSM-tree 比 LevelDB 的更小,也就意味着查找 key 时,需要查找的层数更少;另一方面,LSM-tree 更少,能够缓存的 key 也就更多,因此,命中缓存的概率也就越大。所以,WiscKey 的查询性能往往比 LevelDB 更好。
WiscKey 的思想看起来很简单,但是其中存在很多挑战。
3.3 Challenges
3.3.1 Parallel Range Query
在 LevelDB 中,由于 key-value 有序存放在一起,范围查询时,可以顺序读取 SST。然而,在 WiscKey 中,key-value 分离存储,范围查询时,需要随机读取 vlog 中的 value,这是很低效的。
WiscKey 利用 SSD 并行 IO 特性,多线程随机读也能达到顺序读的效果,如下:
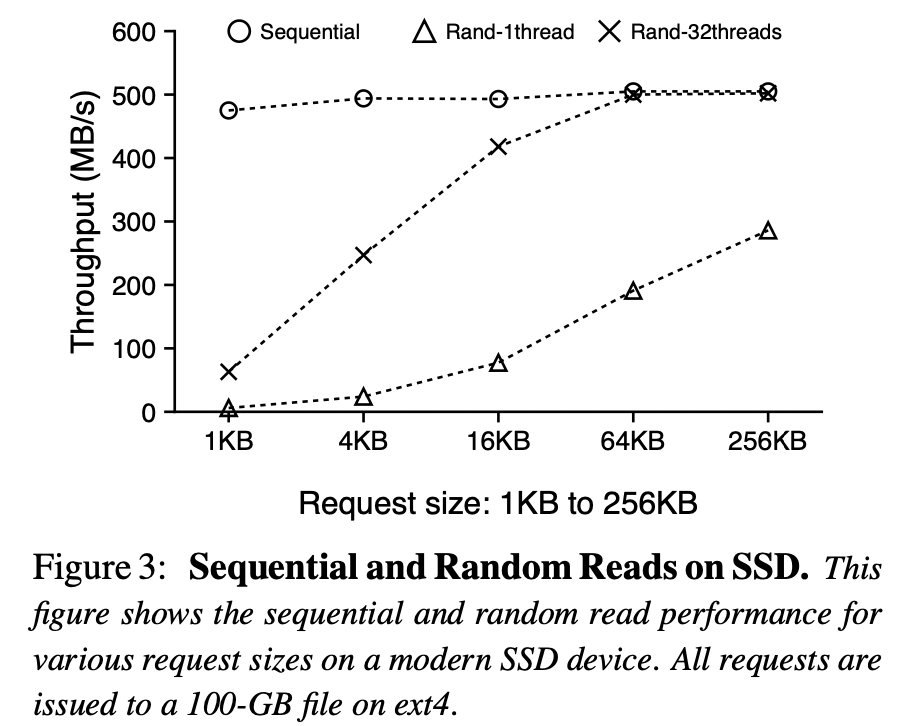
在范围查询时,在 LSM-tree 中预取多个 key-address,然后将 addresses 插入到队列中。多个线程消费队列,得到地址并在 vlog 中并行读取地址对应的 value,从而提升范围查询性能。
3.3.2 Garbage Collection
在标准的 LSM-tree 中,compaction 可以清理掉被删除或者更新前的 key-value。但是在 WiscKey 中 compaction 只能清理掉 keys,values 存放在 vlog 中无法被清理,因此,需要一个特定的垃圾回收器清理 vlog。
一种直观的想法是,scan LSM-tree 获取所有有效的 value 地址,vlog 中的 value 在 LSM-tree 中没有对应有效地址的被视为无效,然后被清理。然而,这种方法太重,只适合作为线下垃圾回收器。
WiscKey 旨在构建一个轻量的在线垃圾回收器,为了实现这一目的,WiscKey 对 layout 做了微小的改变:在 vlog 中将 key 和 value 一起存储,如下:

数据从 head 开始往后追加,垃圾回收器从 tail 开始清理,vlog 中有效数据包含在 head 和 tail 之间,查询是只会查找这个范围内的数据。
垃圾回收时,从 tail 开始读取一个 chunk 的 key-value,然后根据 key 在 LSM-tree 查找检查是否有效,如果有效则将对应的 key-value 追加到 head 后面。当 chunk 中的数据都检查完毕后,清理释放掉整个 chunk,同时更新 tail 指针。
为了防止在 gc 过程中系统崩溃丢失数据,WiscKey 将会执行如下步骤,新的有效值追加到 vlog 后,将调用 fsync() 保证数据落盘。然后将 value 对应的地址和 tail 以同步插入的方式添加到 LSM-tree。最后,释放掉 gc 后的空间。
3.3.3 Crash Consistency
原生的 LSM-tree key-value 在一起,容易保证数据插入和恢复的一致性,WiscKey 中 key-value 的插入分成了两步,一致性保证更复杂。那么如何保证崩溃一致性呢?总结来说,分成下面几种情况:
- value 部分写入后崩溃
- value 写入成功,key-offset 还没有写入到 LSM-tree 中,系统崩溃
- Key-offset 写入 LSM-tree 的过程中崩溃,地址写入不全
第一种情况,value 不全,能够很容易检查出不合法,随后会被 gc 掉;第二种情况,value 虽然写入成功,但是在 gc 的过程中在 LSM-tree 中找不到对应的 key,也会被 gc 掉;第三种情况,地址写入不全,在 gc 时,会检查地址是否在 head 和 tail 范围区间,如果合法会继续比对地址对应的 key 是否匹配,如果不匹配则认为 key 无效,然后从 LSM-tree 中删除掉。
3.4 Optimizations
3.4.1 Value-Log Write Buffer
每次写 vlog 都会调用一次 write() 系统调用,大量的小 io 不利于系统吞吐,解决的方式就是增加一个 vlog 的写缓存,当缓存达到一定阈值时在一把刷入磁盘。查询时,先读缓存,然后再读磁盘。当然,这种方式在系统崩溃时,有丢数据的风险。
3.4.2 Optimizing the LSM-tree Log
在 LevelDB 中会使用 WAL 保证系统在崩溃后能够恢复最近写入的数据。WiscKey 中 vlog 天然有 WAL 的功能,因此 WAL 文件可以省略掉。当 LSM-tree 中的 keys 落盘前系统崩溃,可以从 vlog 中读取数据恢复 keys。
最基础的方式是 scan 整个 vlog 重建 LSM-tree,这种方法太重,不可取。因为我们只需要从最近落盘时点开始恢复,WiscKey 会周期性的将 head 记录到 LSM-tree 中,系统启动后,只需要读取 LSM-tree 获取 head,然后恢复 head 到 vlog 末尾间的数据即可。
4 Benchmark
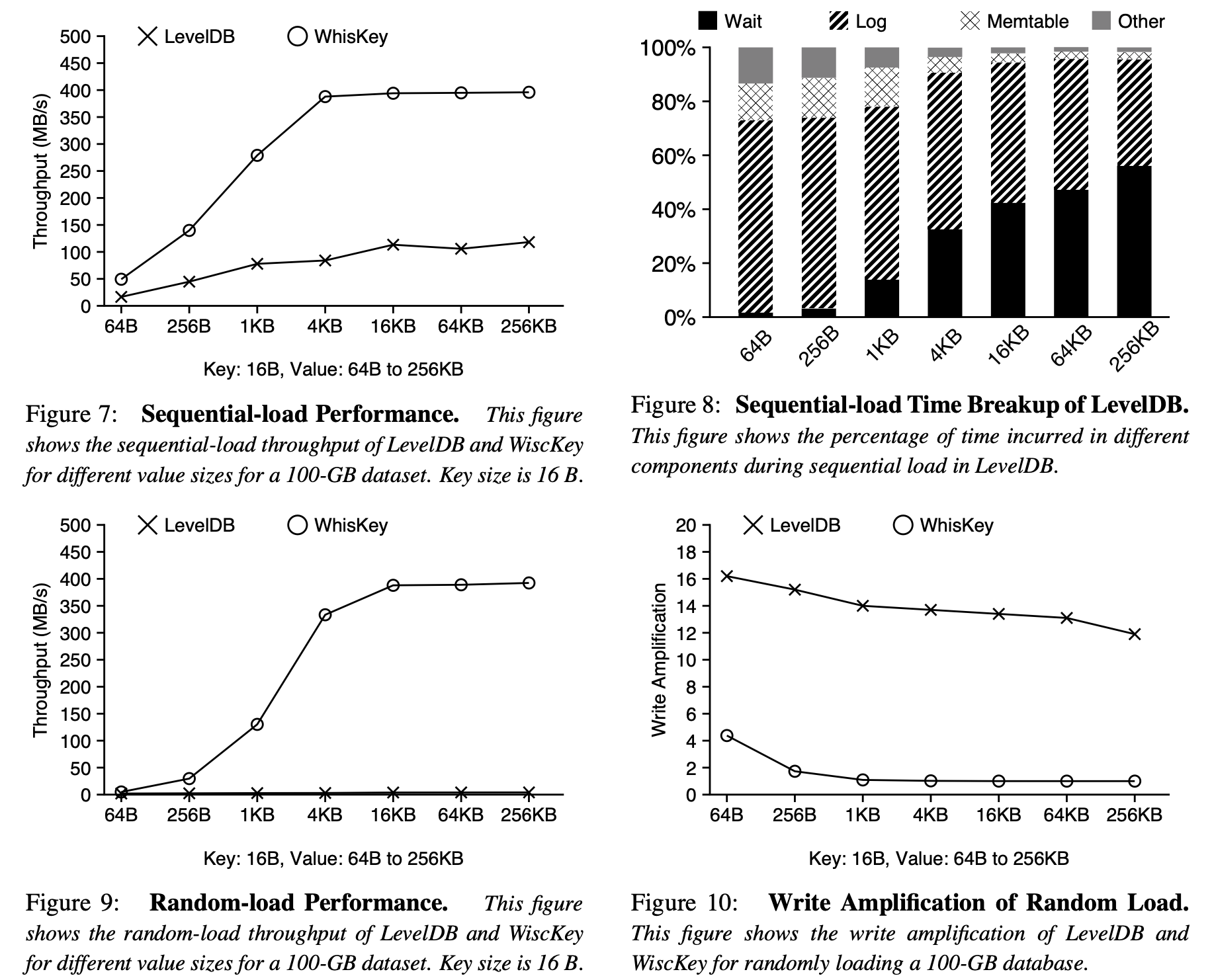
Load Performance
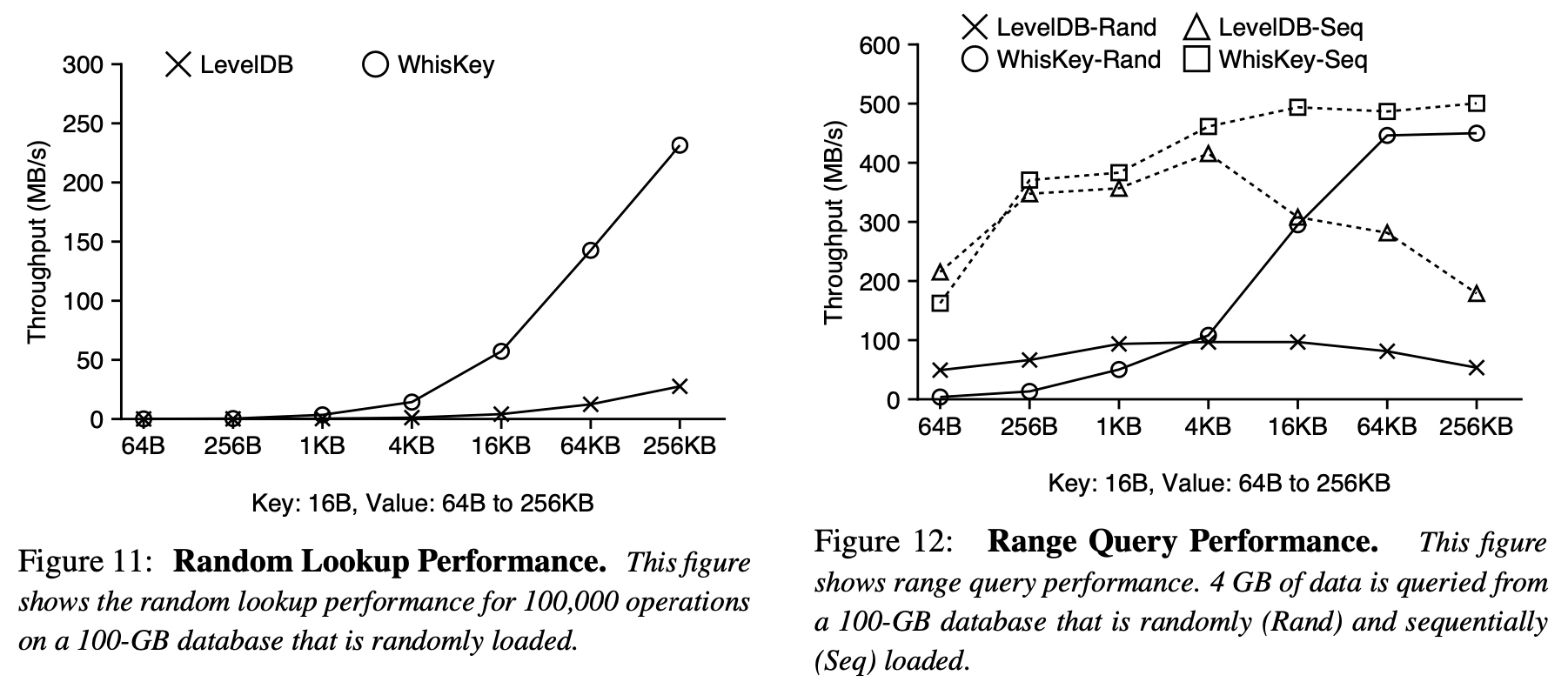
Query Performance
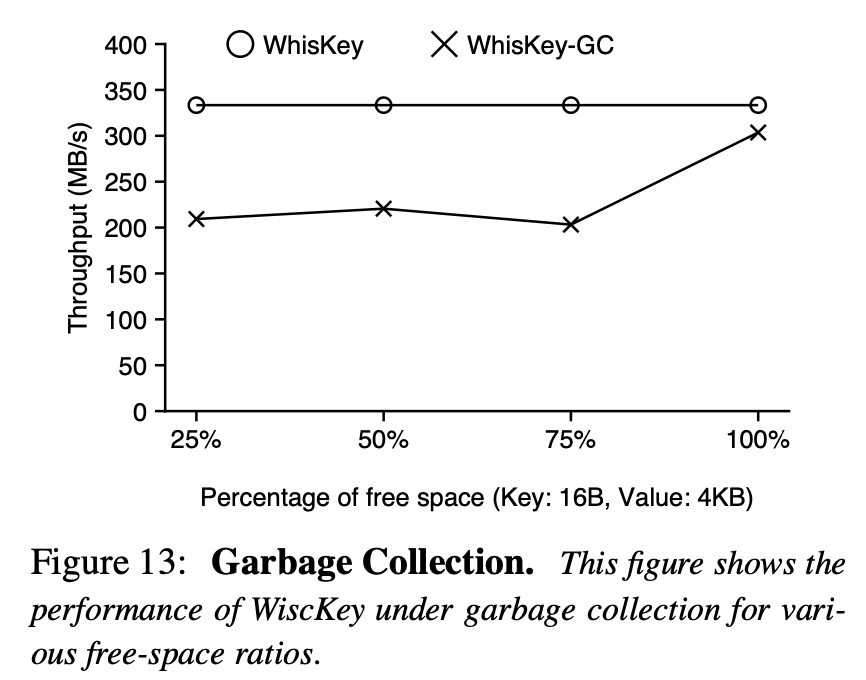
Garbage Collection
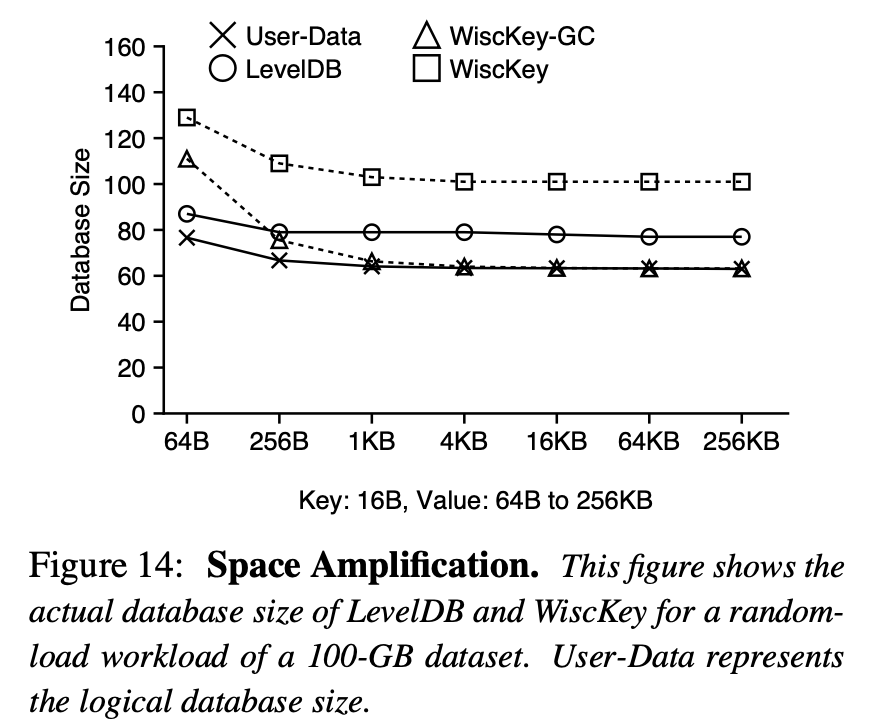
Space Amplification
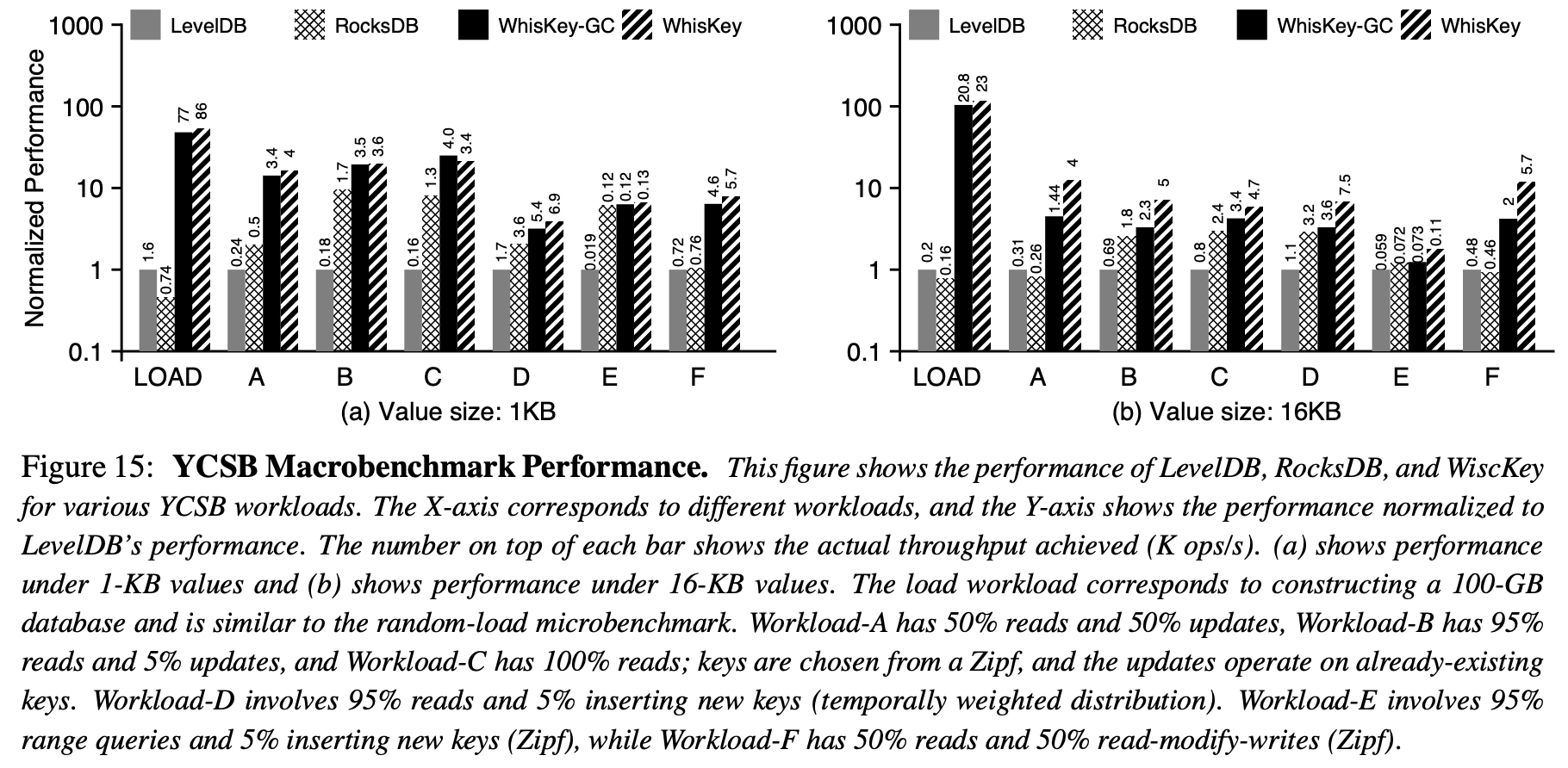
YCSB Benchmarks
Conclusions
WiscKey 的思想比较简单,但是其中有很多细节需要考虑,要实现一款高效的 WiscKey 存储引擎,还是存在很多挑战。目前有几款开源 key-value 存储引擎实现了 WiscKey,后面再深入研究。