lucene DocValues之SortedDocValues
整体思路
为了方便理解 SortedDocValues 的存储原理,本节将通过一个简单的例子来讲解并构造一种简易的存储结构,意在理清 SortedDocValues 的设计思路。
SortedDocValues 要存的是 docIDs 及其对应的 fieldValues,fieldValue 的类型为字节数组。举个例子,假如有如下文档:
| doc | sdv_field | other_field |
|---|---|---|
| 0 | Luce | Based on luceneIn action |
| 1 | Lucene | |
| 2 | Just | |
| 3 | Lu | Go |
| 4 | Lucene | Search engine |
以 sdv_field 为例,如果在内存里面表示 doc 和对应的 fieldValue,最直观想到的是使用 HashMap 来存储。那么内存里面的数据为:
HashMap: {<0, Luce>, <1, Lucene>, <3, Lu>, <4, Lucene>} // key 为 docID,value 为 term
磁盘上的数据为:
docIDs: 0 1 3 4
terms: Luce Lucene Lu Lucene
offsets: 0 4 10 12 18
bitmap: 0000 0000 0001 1011
上述存储方式有什么缺陷?
- 缺陷1:有 terms 重复存储,假如有大量重复的 terms,那么会导致存储(内存及磁盘)空间严重浪费
- 缺陷2:terms 没有规律,按写入顺序存储,压缩效果不好
好了,解决缺陷1的方式很容易想到,通常的做法就是使用字典编码,fieldValues 存储相应的编号即可;解决问题2的方式可以先将 terms 排序,然后前缀编码后再整体压缩。这样一来,在内存中的结构为:
HashMap: {<0, 0>, <1, 1>, <3, 2>, <4, 3>} // key 为 DocID,value 为 termID
idToTerm: {<0, Luce>, <1, Lucene>, <2, Lu>} // key 为 termID,值为 term
ordMap: {<0, 1>, <1, 2>, <2, 0>, <3, 2>} // key 为 termID, 值为 ord
磁盘上的数据为:
docIDs: 0 1 3 4
ords: 1 2 0 2
termDict: Lu Luce Lucene // 排序存储为了更好的编码效率,编码后应该是 Lu ce cene,这里为了方便理解,还是展示原始值
offsets: 0 2 6 12
这里主要关注磁盘结构,假如要查找 doc 4 对应的 term:
- 首先在 docIDs 中查找 doc 4 是否存在,如果不存在则直接返回空,当然这里存在,找到其在序列中的偏移为 3
- 在 ords 相同的偏移处取出 ord 2
- 在 offsets 位置 2 和 3 处取出 offset 6 和 12
- 从 termDict 位置 6 开始取到 12,得到 term 为 Lucene
通过上述例子,可以形象地理解 termID 和 ord 的概念和作用。termID 是 term 的插入顺序编号,在内存中凡是使用 term 的地方都可以使用 termID 替代,从而节约内存。ord 是 term 排序后的编号,代表了 term 的字典序,在磁盘上 ord 就是 term 在 termDict 中的相对位置,从而可以更快地定位查找数据。
另外还有个作用是,由于 termID 和 ord 都是递增生成的。因此内存中可以使用数组替换 HashMap,不仅节约内存,而且效率更高。
内存结构
上面介绍了 termID 和 ord 的作用及构造了一种内存结构和磁盘结构,其实这就是 lucene 的实现思路,只是在实现上,lucene 做得更精细。下面来看看 SortedDocValues 在 lucene 中是如何实现的。
来看下 SortedDocValues 的内存结构:
class SortedDocValuesWriter {
final BytesRefHash hash; // 哈希表,存 termID -> term
private final PackedLongValues.Builder pending; // 临时使用,存所有 termIDs
private final DocsWithFieldSet docsWithField; // 存包含当前 field 的所有 docIDs
private PackedLongValues finalOrds; // 存所有 termIDs,由 pending 压缩编码转变而来。这个变量名取得不严谨,有点迷惑人。docsWithField 和 finalOrds 结合起来可以看做 docIDTOTermsID map
private int[] finalSortedValues; // 按 term 排序后的 termIDs. 下标是 ord,值为 termID
private int[] finalOrdMap; // 存 termID->ord 的映射关系,下标是 termID,值为 ord
}
public void addValue(int docID, BytesRef value) {
// 省略一些不重要的代码
addOneValue(value);
docsWithField.add(docID);
lastDocID = docID;
}
private void addOneValue(BytesRef value) { // value 即 term
int termID = hash.add(value);
if (termID < 0) { // value 已经存在
termID = -termID - 1;
} else {
iwBytesUsed.addAndGet(2 * Integer.BYTES);
}
pending.add(termID);
updateBytesUsed();
}
数据写进来时,先存放在前面 3 个变量中,各变量的作用见注释。flush 时,会调用 SortedDocValuesWriter.finish 方法,生成后面 3 个变量,如下:
private void finish() {
if (finalSortedValues == null) {
int valueCount = hash.size();
updateBytesUsed();
assert finalOrdMap == null && finalOrds == null;
finalSortedValues = hash.sort(); // 返回排序后的 terms 对应的 termIDs. 下标是 ord,值为 termID
finalOrds = pending.build();
finalOrdMap = new int[valueCount]; // 下标是 termID, 值是 ord
for (int ord = 0; ord < valueCount; ord++) {
finalOrdMap[finalSortedValues[ord]] = ord;
}
}
}
注意看 finalSortedValues 是 hash.sort 的结果,返回的值是按 terms 排序后的 termIDs 这个 int 数组,数组的下标就是 ord。因此 ord 其实代表按字典序排序后的 term 的大小序,这和我们上节介绍的概念吻合。
数据最终会 flush 到磁盘,那么在 flush 到磁盘前,内存中的结构如何呢。如下:
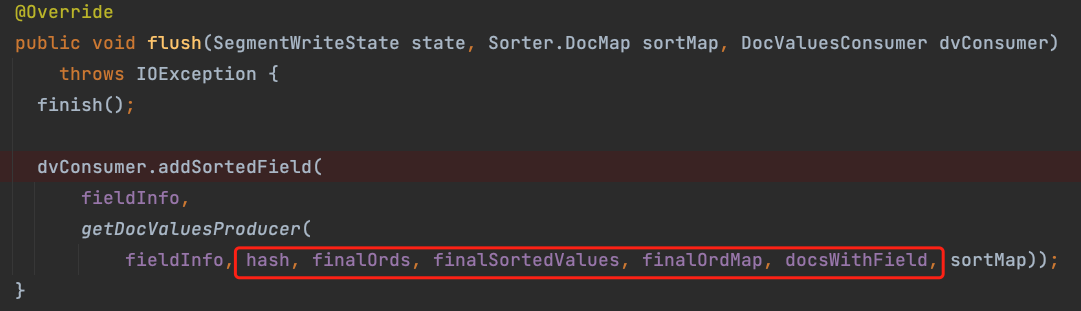
在 flush 时,内存中的数据包含上图 5 个变量。
为了更形象地理解几个变量的含义,举个例子。如下表,有 5 行数据,每行包含字段 sdv_field、other_field。
| doc | sdv_field | other_field |
|---|---|---|
| 0 | Lucene | In action |
| 1 | Elasticsearch | Based on lucene |
| 2 | Just | |
| 3 | Action | Go |
| 4 | Elasticsearch | Search engine |
以 sdv_field 为例,内存数据变化如下:
插入 doc 0
hash
term: Lucene termID 0docsWithField
[0]pending
[0]插入 doc 1
hash
term: Lucene Elasticsearch termID 0 1docsWithField
[0, 1]pending
[0, 1]插入 doc 2
hash
term: Lucene Elasticsearch termID 0 1docsWithField
[0, 1]pending
[0, 1]插入 doc 3
hash
term: Lucene Elasticsearch Action termID 0 1 2docsWithField
[0, 1, 3]pending
[0, 1, 2]插入 doc 4
hash
term: Lucene Elasticsearch Action termID 0 1 2docsWithField
[0, 1, 3, 4]pending
[0, 1, 2, 1]flush
hash
term: Lucene Elasticsearch Action termID 0 1 2docsWithField
[0, 1, 3, 4]finalOrds
[0, 1, 2, 1]finalSortedValues
[2, 1, 0] // 按 term 排序后的 termID,相当于 ord-> termID 的映射,下标是 ord,值是 termIDfinalOrdMap
[2, 1, 0] // termID->ord 映射,下标是 termID,值是 ord
前 5 步是数据在 flush 前的内存存储形式,第 6 步是 flush 时 finish 后的内存存储。以上便是 SortedDocValues 的内存结构,下面会详细介绍 SortedDocValues 在文件中的组织结构。
文件结构
文件 Layout 总览如下图:

dvd
先介绍数据文件 dvd,所有类型的 DocValues 都一样,dvd 由三大部分组成:Header、FieldDocValuesData、Footer。本节着重介绍 FieldDocValuesData 部分,Header、Footer 忽略。
FieldDocValuesData
Field 对应的 docValues 数据,包含四部分:docsWithField、FieldValues、TermsDictData、TermsIndexData。
docsWithField 和 FieldValues 的存储方式和 NumericDocValues 一模一样。只不过,这里 FieldValues 存的是 ords。真实的 term 值存在 TermsDictData 中的,下面会详细介绍。
TermsDictData
TermsDictData 指的是字典数据,实际上存的是排序后的 terms。 数据按 Block 划分存储,64 个 terms 为一个 Block。Block 前缀编码后通过 LZ4 压缩。下面介绍下 Block 中存的内容。
firstTermLength
Block 中第一个 term 的长度。
firstTermValue
Block 中第一个 term 的值。
otherTermsInfo
表示除第一个 term 以外的其他 term 的信息。假如 Block(例如最后一个 Block) 中只有第一个 term,那么这块内容是不存在。来看下这块包含的内容有哪些。
prefixLength | suffixLength-1
prefixLength 表示当前 term 和前一个 term 的共同前缀长度,suffixLength 为后缀长度,即当前 term 的长度减去 prefixLength 。将 prefixLength 和 suffixLength 编码在一起,共用 1 个 byte,从而节省空间。那么这里为什么是 suffixLength-1 呢?
这里引用下源码,方便解释。
bufferedOutput.writeByte(
(byte) (Math.min(prefixLength, 15) | (Math.min(15, suffixLength - 1) << 4)));
if (prefixLength >= 15) {
bufferedOutput.writeVInt(prefixLength - 15);
}
if (suffixLength >= 16) {
bufferedOutput.writeVInt(suffixLength - 16);
}
bufferedOutput.writeBytes(term.bytes, term.offset + prefixLength, suffixLength);
把一个 byte 分成低 4 位和高 4 位,prefixLength 存低 4 位,suffixLength 存高 4 位。
注意,低 4 位为 15(二进制:1111)时,此时该值并不表示 prefixLength,而表示 prefixLength >= 15。其实比较好理解,因为 4 位最大表示 15,因此,[0, 14] 区间的值可以正常表示;大于等于 15 时,用标识 15 表示;由于 15 已经用作标识,所以不能表示 prefixLength。
同理,高 4 位为 15 时,也是用作标识,并不表示 suffixLength。但高 4 位存的是 suffixLength - 1 的值,因为必满足 suffixLength > 0 (dict 存的是 term 的唯一值),因此,suffixLength 为区间 [1, 15] 时,可以正常表示。
prefixLength-15
共同前缀长度减去 15 后的值,很明显减 15 是为了节省空间。
suffixLength-16
同上。
suffixValue
除去前缀后余下的后缀值。
BlockAdress
Block 在文件中的偏移地址,是一个递增的数组,通过 DirectMonotonicWriter 编码存储。
DirectMonotonicWriter 介绍见 链接 。
TermsIndexData
好了,根据 docID 可以找到对应的 ord,进而找到 term。那么反过来,要根据 term 查找其对应的 ord 该怎么办呢?当然可以将 TermsDictData 的每个 Block 解压出来,然后二分遍历查找。假如要查找的 term 比较靠后,那么将要解压+二分查找很多 Block,开销非常大。
更好的方式是什么呢,那就是对 terms 建立索引。lucene 的做法是,每 1024 个 terms 为一组,取出前一组的最后一个 term 和当前组的第一个 term,然后计算前缀值并加上当前 term 的后缀值的第一个 byte 建立稀疏索引。这么说有点抽象,举个例子:
第一组:{"abc", "abcd", ... , "bird"}
第二组:{"birger", "birguz", ... , "chooce"}
第三组:{"chorm", "chorg", ... , "debug"}
第四组:{"dog", "down", ... , "lucene"}
取第一组最后一个 term 值 “bird”,第二组第一个值 “birger”,计算前缀为 “bir”,再加上后缀第一个 byte 结果为 “birg”
取第二组最后一个 term 值 “chooce”,第三组第一个值 “chorm”,计算前缀为 “cho”,再加上后缀第一个 byte 结果为 “chor”
取第三组最后一个 term 值 “debug”,第四组第一个值 “dog”,计算前缀为 “d”,再加上后缀第一个 byte 结果为 “do”
得到最终的索引数据为 [“birg”, “chor”, “do”]
假如查询 term 值为 “boss”,由于 “boss” 介于 “birg” 和 “chor” 之间,所以应该在第 1024 和 第 2048 区间查找 term,即第 16 到 32 个 Block 间查找。通过索引,可以极大缩小查找范围,提高查找效率。
prefixValue
即上面说的相邻两组间后一组第一个 term 和前一组最后一个 term 的共同前缀值加后缀第一个字符。
offset
每个 prefixValue 对应的偏移,prefixValuesOffsets 通过 DirectMonotonicWriter 编码存储。
dvm
dvm 是 dvd 的元数据,由三部分构成:Header、FieldMeta、Footer。本节着重介绍 FieldMeta 部分,Header、Footer 忽略。
FieldMeta 第一部分数据和 NumericDocValues 的元数据一致,这里不过多介绍,主要介绍 TermsDictMeta 和 TermsIndexMeta。
TermsDictMeta
TermsDictData 的元数据,下面详细介绍。
size
ords 的个数,和 docIDs 的个数相同。
DIRECT_MONOTONIC_BLOCK_SHIFT
创建 DirectMonotonicWriter 所需,决定了 DirectMonotonicWriter 内部 buffer 大小。
DirectMonotonicWriterMeta
DirectMonotonicWriter 编解码 TermsBlockAddress 所需元数据(注意,这里可能会有多个,上图只画了一个),来看看具体包含哪些值。
min
待编码数组中的最小值。
avgInc
数组的平均增长值。
offset
DirectMonotonicWriter 当前 block 的偏移相对起始位置的偏移 (DirectMonotonicWriter 内部可能会触发多次 flush,因此可能产生多个 block)。
bitsRequired
每个值所占 bits 数。
maxLength
最大 term 长度。
TermsBlockMeta
maxBlockLength
最大 Block 长度。
offset
TermsDictData 在 dvd 中的偏移。
length
TermsDictData 的长度。
TermsBlockAddressMeta
offset
TermsBlockAddress 在 dvd 中的偏移。
length
TermsBlockAddress 的长度。
TermIndexMeta
TERMS_DICT_REVERSE_INDEX_SHIFT
移位数 10,代表一个 block 有 1024 个 terms。
DirectMonotonicWriterMeta
DirectMonotonicWriter 编解码 prefixValuesOffsets 所需元数据,详细参数前面已介绍过。
prefixValuesMeta
offset
prefixValues 在 dvd 中的偏移。
length
prefixValues 的长度。
prefixValuesOffsetsMeta
offset
prefixValuesOffsets 在 dvd 中的偏移。
length
prefixValuesOffsets 的长度。
总结
本文介绍了 SortedDocValues 的内存结构和磁盘结构,并通过例子构建了一种简易的存储结构,帮助理解 SortedDocValues 的设计原理。可以看到 SortedDocValues 和 NumericDocValues 大部分地方是相似的,只是多了 TermsDict 和 TermsIndex 两部分,大家可以结合前面 NumericDocValues 的文章一起看,更易理解。